ASDParser algorithm details - Part 2: Local state and operation of
the parsing process
Copyright 2008
James A. Mason
Part of the current state of the algorithm which is
constructing a phrase structure
(See Part 1.) during parsing
will be referred to here as the local state of
the parse. It is represented by an
instance of class ASDParseState,
whose instance variables are listed below. Some explanatory
comments have been
added or expanded here which are not in the actual source code.
public ASDPhraseNode
phraseStructure;
//
the first (header) node in the current phrase structure
public ASDPhraseNode
currentNode;
//
the current node at top level in the phrase structure
public ArrayList currentChoices;
//
the choices for next advance of the parse
public int beginning;
//
the index (with origin 1) of the first node in the
// current subphrase in the top-level list of nodes
// to the right of the header node
public HashMap features;
//
the feature-value pairs for the current top-level subphrase
public boolean unique;
//
indicates whether or not the current top-level
//
subphrase is, so far, uniquely parsed
public
ASDSubphraseStack subphraseStack;
//
stacks the beginning indices for all currently
//
incomplete subphrases
public ASDPhraseNode
nextNodeSubphrase;
//
link to subphrase of next node after current one
//
(if any), to detect possible cases of permanent
//
final advance after the current node
public char advanceCase;
//
the kind of advance about to be applied after the
//
current parse state is put on the backup stack:
//
ASDParser.INITIAL, .FINAL, .DUMMY, or .NONDUMMY
An ASDParseState instance
is used in applying one of the four possible sub-algorithms for
advancing the parse (as indicated by the value of advanceCase).
Such
instances can be stacked to permit backtracking to earlier states
of the parse when the parsing algorithm runs into dead-ends. The
instance variables unique and nextNodeSubphrase
are
used to permit and detect cases of one-time parsing of
uniquely-parsed subphrases that do not need to be re-parsed after the
parser backtracks. nextNodeSubphrase is set in the advance
function, described in Part 3,
and
is used in the backup
function, described in Part 4.
Details
of its use are provided there.
The sub-algorithms for the four different cases of
advancing the parse will now be discussed and illustrated with
diagrams. The cases will be presented in increasing order of
complexity. The first two cases involve minimal modification of
the phrase structure that is being built; so backtracking from or
across instances of those cases is fairly simple. The last two
cases modify the phrase structure significantly, with complications for
later backtracking, if necessary.
(1) Simplest of the cases for
advancing is advanceNonDummy, which
advances the parse from the current node at the top level of the phrase
structure to the next node at that level and, in the grammar, to the
non-dummy grammar node that is being taken to correspond to that next
node in the top level of the phrase structure. Here is its entire
source code from ASDParser.java.
the
parameter trynode
is the node in the grammar that the advance is being made to.
void advanceNonDummy(ASDGrammarNode
tryNode)
{
state.currentNode = state.currentNode.nextNode();
state.currentNode.setInstance(tryNode);
state.currentChoices = null;
state.unique = state.unique &&
ASDLexicon.uniqueInstance(state.currentNode.word());
} // end
advanceNonDummy
The value of currentChoices
is set to null in order
to force the overall advance
algorithm of the parser to compute a new set of choices for advancing
from the new state of the parse, after this advance has been
completed. The current subphrase continues to be uniquely parsed,
as indicated by the unique flag,
if it was uniquely parsed up to this point and if the word in the new currentNode at the top level of
the phrase structure has only one instance in the grammar.
Figures 1 and 2 show before and after diagrams of an advance on the
non-dummy kind, for a phrase being parsed with the grammar cardinal.jpg (cardinal.grm).
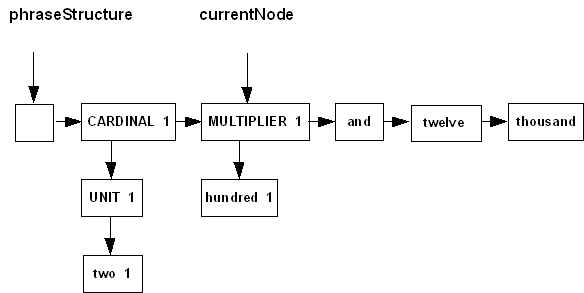
Figure 1
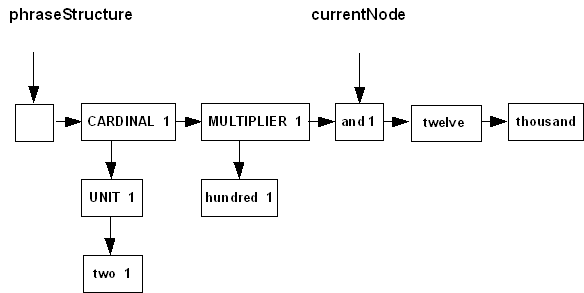
Figure 2
Notice that the currentNode
reference has moved ahead one node at the top level of the
phrase structure, and the instance
reference of that node has been set to 1, corresponding to node [and 1] in the cardinal grammar. (In the
diagram, the instance reference is shown as a number, but in the actual
method advanceNonDummy
it is the value of the tryNode
parameter.) If the parser were to backtrack later on, to a state
before this one in the parsing process, the fact that the instance reference of that node has
been set at this point will just be ignored. The instance
reference will simply be re-set whenever a node in the phrase structure
is re-entered during a parse.
(2) Second simplest of the
cases for advancing the parse is that of advancing to an initial node in the grammar.
Here is the source code for it:
void advanceInitial(ASDGrammarNode
tryNode)
//
Advance to the next node in the phrase structure
//
and to the corresponding node, tryNode, in the
//
grammar:
{
state.currentNode = state.currentNode.nextNode();
state.currentNode.setInstance(tryNode);
//
Save the beginning position, the semantic features
//
table, and the flag which indicates uniqueness of
//
parsing for the suspended subphrase:
state.subphraseStack.push(
new
ASDSubphraseStackFrame(state.beginning,
state.features,
state.unique) );
//
Compute the beginning position for the new subphrase:
state.beginning = 0;
for (ASDPhraseNode node = state.phraseStructure;
node
!= state.currentNode; node = node.nextNode())
++state.beginning;
//
Create a new semantic features table for the new
//
subphrase:
state.features = new HashMap(10);
//
Initialize the uniqueness flag for the new subphrase
//
according to whether or not the first word has only
//
one instance (node) in the grammar and that node has
//
no incoming edges:
state.unique
=
!tryNode.hasIncomingEdges()
&&
ASDLexicon.uniqueInstance(state.currentNode.word());
//
Set currentChoices to indicate that the choices have
//
not been computed:
state.currentChoices = null;
} // end
advanceInitial
This is somewhat similar to advanceNonDummy,
except
that steps have been added to remember things about the
subphrase that was just being parsed, and is now suspended, and to
compute things that are specific to the new subphrase that is being
started.. In particular, the feature-value pairs for the
suspended subphrase -- i.e., the value of state.features - must be
remembered, and a new table for feature-value pairs for the new
subphrase must be initialized. Also, the position at which the
suspended subphrase began must be remembered, and whether or not it was
uniquely parsed so far. All these things are remembered by
pushing them onto the stack named state.subphraseStack.
They will be retrieved from that stack when the suspended subphrase
resumes, after the new subphrase is completed.
After values specific to the suspended subphrase
have been stacked, the position of the beginning of the new subphrase
(at the top level of the phrase structure) is computed (to be used
later when the subphrase ends). Also, a new value for the state.unique flag is computed,
to indicate whether the new subphrase is uniquely parsed, so far.. It
is, if the initial grammar
node for its first word has no incoming edges and is the only instance
of that word in the grammar.
For example, consider an advance from the state of
the phrase structure shown in Figure 2 to the one shown in Figure
3. For the subphrase that started at the node [CARDINAL 1], following the
header node, the value of state.beginning
will be 1, and state.features
will have the feature-value pairs ("V",
2) and ("M", 100), as set previously by the
functions setVNodeValue()
and multiplier_1_action(),
respectively,
when they were invoked from the semantic
action fields of the
grammar nodes [CARDINAL 1]
and [MULTIPLIER 1],
respectively. The value of state.unique
will be false, because
the phrase up to that point is not uniquely parsed. (In
particular, the parse could advance from node [MULTIPLIER 1] to the dummy
node [$$ 2] instead of to
[and 1] at an earlier
stage in the parsing process.
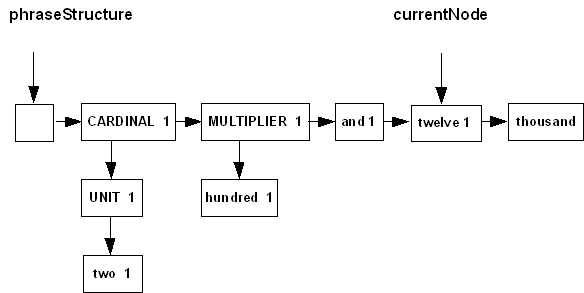
Figure 3
(3) Advancing the parse to a dummy node in the grammar requires
insertion of a corresponding dummy node at the top level of the phrase
structure that is being constructed by the parser. Here is
the source code for it:
void advanceDummy(ASDGrammarNode tryNode)
//
Create a new dummy ASDPhrase node and link it to the
//
next node in the phrse structure:
{
ASDPhraseNode dummy = new ASDPhraseNode();
dummy.setWord(DUMMYWORD);
dummy.setInstance(tryNode);
dummy.setNextNode(state.currentNode.nextNode());
//
Other fields of the dummy node are null by default.
//
Complete the insertion of the dummy node, allowing for
//
possible backup later:
if
(backstack.empty())
//
No backups can occur to states before this state
//
in the parse; so just insert the dummy node
//
after the current node
state.currentNode.setNextNode(dummy);
else
//
Later backup may be required; so copy the top level
//
of the phrase structure up to the place where the
//
dummy node is to be inserted, and insert the
//
dummy node after the copy:
{ ASDPhraseNode temp
=
(ASDPhraseNode)state.phraseStructure.clone();
ASDPhraseNode
prev;
ASDPhraseNode
oldNode = state.phraseStructure;
state.phraseStructure
= temp;
while(oldNode
!= state.currentNode)
{
oldNode = oldNode.nextNode();
prev
= temp;
temp
= (ASDPhraseNode)oldNode.clone();
prev.setNextNode(temp);
}
temp.setNextNode(dummy);
}
//
Advance to the dummy node and set currentChoices to
//
indicate that the choices have not yet been computed:
state.currentNode = dummy;
state.currentChoices = null;
} // end advanceDummy
The insertion of a new top-level node modifies the phrase structure in
a way that must be undone if the parsing algorithm later needs to
backtrack to an earlier point in the parsing process. The advanceDummy
subalgorithm prepares for such possible backtracking by copying the
top-level list of nodes in the phrase structure up to the point at
which the dummy node is inserted, as illustrated in Figures 4 and 5,
which show a phrase structure before and after a dummy-node advance.
![[ example phrase structure before dummy advance]](AdvanceDummyExample1.png)
Figure 4
![[ example phrase structure after dummy advance]](AdvanceDummyExample2.png)
Figure 5
Notice, however, that the copying at the top level of the phrase
structure is performed by the subalgorithm only if the expression backstack.empty()
is false. The
variable backstack
refers to a data structure that keeps track of the earlier local parse
states, in last-in-first-out order, to which the algorithm may have to
backtrack. It is part of the global
state of the parsing process, discussed in Part 3 of these
notes. A copy of the entire ASDParseState,
whose
instance variables were listed at the beginning of this part of
the notes, is put on top of the backstack
when an advance is performed over which the parser may need to
backtrack later on. The ASDParseState
includes the old values of phraseStructure and currentNode,
shown
in Figure 4, in contrast to their new values shown in Figure
5. Thus, the phrase structure in Figure 4 can be recovered from
the one in Figure 5 during backtracking just by restoring the old
values of phraseStructure and currentNode.
In
that case, the new nodes in the top-level copy in Figure 5 can be
left for garbage collection by the Java run-time system after the
backtrack has occurred.
(4) Advancing the parse from a final node in the grammar is the
most complicated kind of advance that the ASD parser performs. It
involves replacing one or more nodes at the top level of the phrase
structure, which make up the subphrase that has been completed, by a
single node labeled with the phrase type of the completed phrase.
The nodes removed from the top level must then be hung below the new
single node at the top level. All of that makes for a more
complicated change of the phrase structure than occurs in a case of
advance to a dummy node.
Figure 6 provides an example of a final advance from the node [$$ 1] in Figure 5 and
the corresponding final node in the grammar cardinal.jpg.
It
shows only the copying which occurred in Figure 5 and which occurs
as part of the final advance;
that is, it does not show copying that may have occurred lower down in
the phrase structure, earlier in the parse. Notice that after the
advance, currentNode points to
the node just before the node
that has been inserted at the top level to represent the completed
subphrase of type CARDINAL.
That
allows the parser to use
the new node immediately, if possible, to continue the subphrase that
was suspended at the top level when the newly completed subphrase
(starting with node [DECADE 1]
began). The advanceFinal subalgorithm
also retrieves from the subphrase stack (See advanceInitial
in (2) above.) the indicator of the beginning of the resumed subphrase,
as well as its table of feature-value
pairs and a flag that indicates whether or not it has been uniquely parsed so far.
The example in Figure 6 also shows why the beginnings of subphrases are
represented by position numbers of nodes at the top level in the phrase
structure, rather than pointers to them. That is because the node
that begins a suspended subphrase will often have been copied at the top level of the
phrase structure before the parser resumes the recognition of that
subphrase.
![[ example phrase structure after a final advance ]](AdvanceFinalExample1.png)
Figure 6
There is still more to the complexity of the subalgorithm advanceFinal.
The
following is its full source code:
/**
Carries out an advance of the Final kind,
replacing a completed subphrase at the top level
of
the phrase structure by a single node whose
"word" is the type of phrase that was completed.
@return SUCCEED if successful, NOADVANCE if unsuccessful
but the parse should continue after backup,
QUIT if the parse should quit.
*/
String advanceFinal(String phraseType)
{ String val
=
state.currentNode.instance().semanticValue();
//
Evaluate the semantic value
Object computedValue = null;
String computedString = null;
if
(semantics != null && val != null && val.length() >
0)
computedValue
= semantics.semanticValue(val);
else // no class for computing semantics
computedValue
= val;
if
(computedValue instanceof String)
if
(computedValue == NOADVANCE || computedValue == QUIT)
return
(String) computedValue;
//
Find the beginning of the completed subphrase:
ASDPhraseNode prev = state.phraseStructure;
for (int j = 1; j < state.beginning; ++j)
prev
= prev.nextNode();
ASDPhraseNode first = prev.nextNode();
if
(!saveUniquelyParsedSubphrases
||
(!state.unique && !backstack.empty()))
//
Create a new node to represent the entire completed
//
subphrase at the top level in the phrase structure:
{ ASDPhraseNode newNode = new ASDPhraseNode();
newNode.setWord(phraseType);
newNode.setValue(computedValue);
//
instance field is null by default
newNode.setNextNode(state.currentNode.nextNode());
//
Copy the top level of the subphrase, set
//
the next link of the last node in the copy to null,
//
and hang the copied subphrase below the new node:
ASDPhraseNode
temp = (ASDPhraseNode)first.clone();
newNode.setSubphrase(temp);
ASDPhraseNode
oldNode = first;
while(oldNode
!= state.currentNode)
{
oldNode = oldNode.nextNode();
prev
= temp;
temp
= (ASDPhraseNode)oldNode.clone();
prev.setNextNode(temp);
}
temp.setNextNode(null);
//
Copy the nodes of the phrase structure that precede
//
the completed subphrase, and set the next link of
//
the last of those nodes to point to the new node:
temp
= (ASDPhraseNode)state.phraseStructure.clone();
oldNode
= state.phraseStructure;
state.phraseStructure
= temp;
while(oldNode.nextNode()
!= first)
{
oldNode = oldNode.nextNode();
prev
= temp;
temp
= (ASDPhraseNode)oldNode.clone();
prev.setNextNode(temp);
}
temp.setNextNode(newNode);
//
Set the current node to the one just before the
//
new node:
state.currentNode
= temp;
}
else // uniquely parsed subphrases are to be saved,
//
and the subphrase is uniquely parsed
//
or no backtracking will be required.
//
Replace the completed subphrase permanently by
//
a single node at the top-level of the phrase
//
structure. To allow for proper backtracking,
//
if required, let that single node be the old
//
first node of the subphrase, with the latter
//
replaced by a new node that is a copy of it:
{ ASDPhraseNode newNode = (ASDPhraseNode)first.clone();
first.setWord(phraseType);
first.setInstance(null);
first.setSubphrase(newNode);
first.setValue(computedValue);
first.setNextNode(state.currentNode.nextNode());
if
(state.currentNode == first)
//
the completed subphrase has only one node
newNode.setNextNode(null);
else
if (backstack.empty())
state.currentNode.setNextNode(null);
else
// subphrase has more than one node; backstack is not empty.
{
// Copy any nodes after the first node at the top level
//
of the subphrase, and set the next link of the last node
//
in the copy to null. This must be done in case any
//
suspended parses on the backstack have links into
//
the middle of the completed subphrase.
if
(first != state.currentNode)
{
ASDPhraseNode oldNode = newNode.nextNode();
ASDPhraseNode
temp = (ASDPhraseNode)oldNode.clone();
newNode.setNextNode(temp);
ASDPhraseNode
prevTemp = null;
while(oldNode
!= state.currentNode)
{
oldNode = oldNode.nextNode();
prevTemp
= temp;
temp
= (ASDPhraseNode)oldNode.clone();
prevTemp.setNextNode(temp);
}
temp.setNextNode(null);
}
}
//
Set the current node to the one just before
//
the new node:
state.currentNode
= prev;
}
//
Restore characteristics of the resumed subphrase:
ASDSubphraseStackFrame popped
=
(ASDSubphraseStackFrame)state.subphraseStack.pop();
state.unique = popped.unique && state.unique;
//
It is uniquely-parseable if it was unique when
//
suspended and the subphrase just completed was
//
also unique.
state.features = popped.features;
state.beginning = popped.beginning;
//
Compute a new list of currentChoices for the resumed
//
currentNode:
if
(done())
//
If the parse is completed, there should be no more
//
choices at this point; this prevents futile initial
//
advances if a subsequent advance is attempted to
//
find another parse.
state.currentChoices
= null;
else
//
If the parse has not been completed, compute a list
//
of choices, but without including dummy advances:
state.currentChoices
= choices(false, null);
return SUCCEED; // successful Final advance
} // end advanceFinal
The main additional complication in advanceFinal
has to do with how uniquely-parsed
subphrases are handled. The parser considers any sequence
of words ("Word" here refers to actual words or phrase types.) that
constitutes a recognizable subphrase in the grammar being used, to be uniquely parsed if there is no
other way that sequence of words could be used in a successful
parse of the overall phrase. In that case, the parser can, at the
option of the user, make a permanent
replacement of the subphrase at the top level of the phrase structure,
in a way that will survive possible later backtracking to positions
before that subphrase in the phrase structure. For example,
suppose the parser advances the parse several more steps, from the
situation shown in Figure 6 to the one shown in Figure 7.
![[ example phrase structure before permanent final advance ]](AdvanceFinalExample2.png)
Figure 7
Because the word "thousand"
has
only one instance in the grammar cardinal.jpg,
and
because it is both an initial
and a final node in the
grammar, there is only one way in which it can be part of a subphrase:
namely as an entire subphrase of type "MULTIPLIER". So, provided
the user of the parser wishes, "thousand"
can
be replaced permanently
at the top level of the phrase structure by a node containing its
phrase type. That is, it is a uniquely-parsed
subphrase. To do the replacement permanently, however, the
parser must see to it that all of the pointers to node [thousand 1] in Figure 6
are adjusted to point to the new top-level node. Rather than
tracking down all of the pointers to node [thousand 1], the parser
uses an old trick known to LISP programmers who want to insert a new
node at the beginning of a list that has multiple pointers to it:
- Make a copy (clone) of
the first node in the list.
- Insert the copy after
the first node in the list.
- Put the desired new contents into the first node in the list.
That leaves all of the pointers pointing to the first node, which is
now the new node (because of its new contents) and is followed by (a
copy of) the old first node. Similarly, the ASDParser makes a
copy of the node [thousand 1], hangs it below the old node [thousand 1], and then puts the
phrase type "MULTIPLIER"
into the old node, as shown in Figure 8.
![] example phrase structure after permanent final advance ]](AdvanceFinalExample3.png)
Figure 8
This completes discussion of the four ways in which ASDParser can
advance the local state of a parse and update the phrase structure
diagram. Further details of the algorithm for advancing the
parse, and the variables that represent the global state of the parse, are
discussed in Part 3.
ASD Parser algorithm details -
Contents
ASD notes and documentation
ASD home page
last modified 2010 Aug 21