 LetterGuessingExperiment
LetterGuessingExperiment
|
|||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | ||||||
| SUMMARY: NESTED | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | ||||||
java.lang.Object
public class LetterGuessingExperiment

For the guessing mode described above, the participant is allowed one guess per letter.
Shannon also describes a second guessing mode, where the participant continues to guess until the correct letter is determined:

Both modes are implemented in this software.
Click here for instructions on launching/running the application.

The default parameter settings are read from a configuration file called
LetterGuessingExperiment.cfg. This file is created automatically when the
application is launched for the first time. The default parameter settings may be changed through
the setup dialog. The setup parameters are as follows:
Parameter Description Participant Code Identifies the current participant. This is used in forming the names for the output data files. Also, the sd2 output data file includes a column with the participant code.
Condition Code An arbitrary code used to associate a test condition with this invocation. This parameter might be useful if the software is used in an experiment where a condition is not inherently part of the application (e.g., Gender → male, female). The condition code is used in forming the name for the output data file. Also, the sd2 output data file contains a column with the condition code. Note: The setup dialog does not include an entry for "Block code". The block code is generated automatically by the software.
Number of Phrases Specifies the number of phrases presented to the participant in the current block.
Phrases File Specifies the file from which phrases are selected for input. Phrases are drawn from the file at random. Typically, phrases2.txtis used. This is the phrase set published by MacKenzie and Soukoreff in 2003 (click here).
Beep on Error A checkbox item that, if set, configures the application to output an audible beep when the user makes an incorrect guess.
Guessing Mode Set the guessing mode, as per the two modes described by Shannon (see above).
The two guessing modes are as follows:
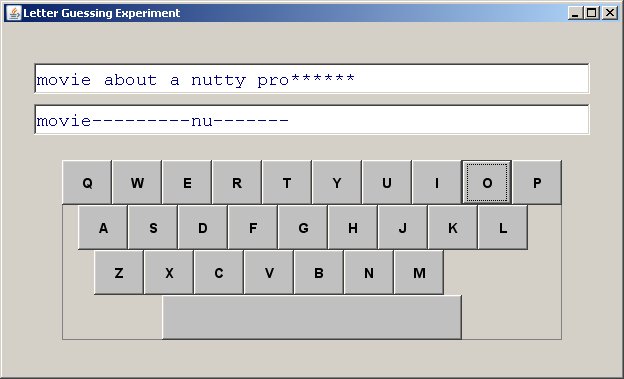
The text to guess is presented in the top line. It appears initially as a string of asterisks. The text is revealed letter by letter as guessing proceeds. The text in the second line is what Shannon called the "reduced text". Here, a dash indicates a correct guess, a letter indicates an incorrect guess.
Typical results popup:
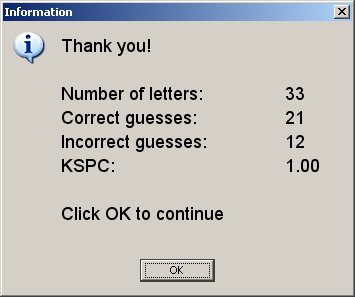
KSPC is "keystrokes per character", computed as
KSPC = (correct + incorrect) / number_of_letters

For the correct-guess mode, the count is shown as a single character in the reduced text (second line). Counts above 9 appear as A (10), B (11), C (12), etc. Keys are darkened for incorrect guesses, as a reminder to the participant of letters already visited.
Typical results popup for the correct-guess mode:

Here, the number of correct guesses is always equal to the number of letters in the presented text. KSPC is very likely > 1, since the participant is likely to guess incorrectly, at least some of the time. (But, who knows, some people are pretty good at this. Click here to see an example from Wheel of Fortune.)
The data in the sd2 files are full-precision, comma-delimited. Importing into a spreadsheet application provides a convenient method to examine the data on a phrase-by-phrase basis. The data in the sd2 example file above (correct-guess mode), are shown below as they might appear after importing into Microsoft Excel: (click to enlarge)

Actual output files use "LetterGuessingExperiment" as the base filename. This is followed by the
participant code, the guessing mode, the condition code, and the block code, for example,
LetterGuessingExperiment-P01-One_guess-C01-S01-B01.sd2.
pict 14739
pica 9143
pick 6907
pic_ 3598
pici 3498
pics 1838
picu 749
picn 567
The language model would work well here, since "t" is the first choice. Unfortunately, the
language model would not do as well on the next guess, since "u" appears in the third-ranked
quadgram beginning with "ict":
icti 22098
ict_ 15628
ictu 14739
icto 12354
icts 2828
icte 2746
ictl 1885
icta 1591
Furthermore, since humans inherently possess a vast knowledge of idioms and clich�s in their
native language, the user is likely to fair quite well (better than the language model?) as
guessing proceeds deeper into the phrase. For example, most native speakers of English can easily
complete the phrase, "a picture is worth a thousand ______". So, the comparison suggested
— between the language model and the user — could be pursued in an overall sense or
as a function of "position in phrase".
A more advanced language model might use a word list with part-of-speech (POS) tagging, as described in Improved word list ordering for text entry on ambiguous keyboards (Gong, Tarasewich, and MacKenzie, NordiCHI 2008).
The timestamp data might be useful in revealing how thoughtful the user was. Did the user think carefully about the guesses, or did the user appear to be hurried and guessing randomly?
| Constructor Summary | |
|---|---|
LetterGuessingExperiment()
|
|
| Method Summary | |
|---|---|
static void |
main(java.lang.String[] args)
|
| Methods inherited from class java.lang.Object |
|---|
equals, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait |
| Constructor Detail |
|---|
public LetterGuessingExperiment()
| Method Detail |
|---|
public static void main(java.lang.String[] args)
throws java.io.IOException
java.io.IOException
|
|||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | ||||||
| SUMMARY: NESTED | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | ||||||