MacKenzie, I. S. (1995). Input devices and interaction techniques for advanced computing. In W. Barfield, & T. A. Furness III (Eds.), Virtual environments and advanced interface design, pp. 437-470. Oxford, UK: Oxford University Press.
Input Devices and Interaction Techniques for Advanced Computing
I. Scott MacKenzie
Dept. of Computing & Information ScienceUniversity of Guelph
Guelph, Ontario, Canada N1G 2W1
Introduction
One enduring trait of computing systems is the presence of the human operator. At the human-computer interface, the nature of computing has witnessed dramatic transformations--from feeding punched cards into a reader to manipulating 3D virtual objects with an input glove. The technology at our finger tips today transcends by orders of magnitude that in the behemoth calculators of the 1940s. Yet technology must co-exist with the human interface of the day. Not surprisingly, themes on keeping pace with advances in technology in the human-computer interface and, hopefully, getting ahead, underlie many chapters in this book. The present chapter is no exception. Input devices and interaction techniques are the human operator's baton. They set, constrain, and elicit a spectrum of actions and responses, and in a large way inject a personality on the entire human-machine system. In this chapter, we will present and explore the major issues in "input", focusing on devices, their properties and parameters, and the possibilities for exploiting devices in advanced human-computer interfaces.
To place input devices in perspective, we illustrate a classical human factors interpretation of the human-machine interface (e.g., Chapanis, 1965, p. 20). Figure 1 simplifies the human and machine to three components each. The internal states of each interact in a closed-loop system through controls and displays (the machine interface) and motor-sensory behaviour (the human interface). The terms "input" and "output" are, by convention, with respect to the machine; so input devices are inputs to the machine controlled or manipulated by human "outputs". Traditionally human outputs are our limbs--the hands, arms, legs, feet, or head--but speech and eye motions can also act as human ouput. Some other human output channels are breath and electrical body signals (important for disabled users).
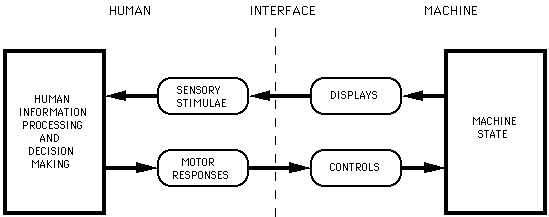
Figure 1. The human-machine interface. Input devices are the controls humans
manipulate to change the machine state.
Interaction takes place at the interface (dotted line in Figure 1) through an output channel--displays stimulating human senses--and the input channel. In the present chapter, we are primarily interested in controls, or input devices; but, by necessity, the other components in Figure 1 will to some extent participate in our discussion.
Two broad themes in this chapter are interaction and technology. A familiar message is that interaction is the key to pushing the frontier and that technology should evolve and bend to serve interaction, rather than interaction conforming to technology. This is a contestable viewpoint. Advances in technology are often independent of the consequences or possibilities for human-computer interaction or other applied disciplines. Basic research fields such as materials science or semiconductor physics push the boundaries of science, addressing fundamental questions and spawning "low-level deliverables" (e.g., semiconductor devices that are smaller, faster, denser, more efficient, etc.). Through engineering and design, deliverables eventually filter up into commercial products (cf. technology). As human factors researchers or human-machine system designers, we should fully expect to mold interaction scenarios within a given resource base--today's technology. Although technological constraints tend to vanish simply by waiting for new advances, interaction problems persist since their solution requires multidisciplinary research and design efforts that are often ill-defined and qualitative. This is where the greatest challenges lie.
In advanced virtual environments, goals are to empower the user, to instrument all or part of the body, and to force the machine to yield to natural dialogues for interaction. In the following paragraphs we will describe the state of the art and identify trends in input devices and interaction techniques. There is a substantial existing resource base upon which to proceed (the time is right!); however, as we shall see, many of the more utopian visions will remain just that until the technology delivers more.
Technology
In this section, we focus on technological characteristics of present and future input devices. While specific devices are cited, the intent is not to list and categorize the repertoire of devices. Previous surveys have adequately summarized tablets, touch screens, joysticks, trackballs, mice, and so on (e.g., Greenstein & Arnault, 1987; Sherr, 1988). Eye tracking as an input technology is discussed in the chapter by Jacob, and will not be included here. Technological considerations presented herein include the physical characteristics of input devices (with examples from real devices), properties that define and distinguish devices, models for summarizing or predicting performance, and parameters that can be measured and controlled to optimize interaction. We begin with the physical characteristics of the transducers embedded within input devices.
Transducers
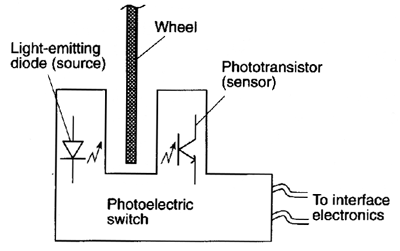
The most simplistic, technology-centered view of input and output devices is at the electro-mechanical level of the transducer. Transducers are energy converters. For input devices the conversion is usually from kinetic energy (motion) or potential energy (pressure) to electric energy (voltage or current). By far the most common input transducer is the switch. The hardware supporting mouse buttons and alphanumeric keys is the most obvious example. Motion applied to the switch opens or closes a contact and alters the voltage or current sensed by an electronic circuit. Many "high-level" devices are an aggregate of switches. The x-y pointing capability of mice and trackballs, for example, is often implemented by photo-electric switches. A beam of light is interrupted by perforations in a rotating wheel driven by the mouse ball or trackball. Light pulses stimulate phototransistors that complete the conversion of kinetic energy to electric energy (see Figure 2).
(b)
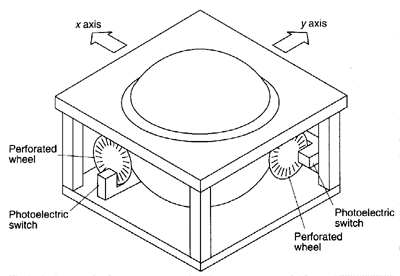
Figure 2. A photo-electric switch as an input transducer. (a) A
light-emitting diode provides a source of light and stimulates a
phototransistor sensor, switching it on and off. The light beam
is interrupted by a rotating perforated wheel. (b) Two photo-electric
switches sense x and y motion of a rolling trackball.
Joysticks are commonly available in two flavors. Displacement or isotonic joysticks move about a pivot with motion in two or more axes. The 544-G974 from Measurement Systems, Inc., for example, is a three axis displacement joystick sensing x and y pivotal motion as well as twist (see Figure 3a). Deflection is +/-15° about the x and y axes and +/-10° of twist.
 (b)
(b) 
Figure 3. (a) A three-axis displacement joystick senses tilt about
the base and twist about the vertical axis. (b) A four-axis isometric
joystick senses force in the x, y, and z axes, and torque in the twist axis.
Force sensing or isometric joysticks employ resistive strain gauges which undergo a slight deformation when loaded. An applied force generates compression or tension in a wire element bonded to a load column. The wire element undergoes compression or tension which changes its resistance. This effects a change in voltage or current in the interface electronics. An example is the 426-G811, also from Measurements Systems, Inc. (see Figure 3b). This four-axis joystick senses x, y, and z force, and torque about the twist axis. Up to 10 lbs of force is sensed in the x and y axes, and 20 lbs in the z axis. Torque up to 32 in.-lbs is sensed in the twist axis. Deflection is slight at 0.65 in. for the x and y axes, 0.25 in. for the z axis, and 9° for the twist axis.
Although most input devices are manually actuated, we should acknowledge the microphone as an important input device. Converting acoustic energy to electric energy, microphones are the transducers that permit us to talk to our computer. Speech input will be mentioned briefly later in connection with multi-modal input; however specific problems in speech input and recognition are beyond the scope of this chapter.
Gloves, 3D Trackers, and Body Suits
The technology underlying many successful input devices, such as the mouse or QWERTY keyboard, is mature and stable. Of greater interest to this book's audience is the requisite technology of future input devices. Body suits and input gloves represent two input technologies holding tremendous promise in bringing technology to interaction. Juggling or conducting an orchestra are human activities with the potential of entering the world of human-machine dialogues; yet, significant inroads--on purely technological grounds--must be achieved first. Applications such as these do not exist at present, except in a primitive form in research labs. A challenge for researchers is to get the technology into the mainstream as an entertainment medium or a means of performing routine tasks in the workplace.
Devices such as gloves and body suits are really a compliment of transducers working in unison to deliver fidelity in the interface. Most gloves combine a single 3D tracker and multiple joint sensors. The DataGlove by VPL Research, Inc. is a thin lycra glove with a magnetically coupled 3D tracker mounted on it (see Figure 4). Bending in the two proximal joints is measured by the attenuation of a light signal in each of two fiber optic strands sewn along the fingers and thumb. Position and orientation measurements are accurate to 0.13 inches RMS and 0.85° RMS at 15 inches. Data are transfered over RS232 or RS422 links at rates up to 38.4 kilobaud. Sampling rate is 30 Hz or 60 Hz. The DataGlove, first introduced at CHI '87 by Zimmerman, Lanier, Blanchard, Bryson, and Harvill (1987)[1], was the first input glove to gain widespread use in the research community (although earlier devices date from about 1976; see Krueger, 1991, chap. 4). Options are available for abduction sensing (on the thumb, index, and middle fingers) and force feedback.
The DataGlove has been criticized because of its non-linear mapping between joint movement and the intensity of the reflected light (Green, Shaw, & Pausch, 1992). As well, the lack of abduction sensing (on the standard model) limits the number of hand positions that can be detected, for example, in gesture recognition tasks (Fels & Hinton, 1990; Takahashi & Kishino, 1991; Weimer & Ganapathy, 1989).

Figure 4. The VPL DataGlove. Two optical strands are sewn along
each finger to sense bend in two joints. A single strand sewn on the
thumb senses single joint motion.
The CyberGlove by Virtual Technologies includes 22 resistive-strip sensors for finger bend and abduction, and thumb and pinkie rotation. The mapping is linear with 8 bits of resolution per sensor (see Figure 5). A force feedback option is available. The strip sensors are a more natural transducer for sensing bend and abduction than the optical fibres in the VPL DataGlove. Their presence is less apparent, more comfortable, and easily extends to applications beyond the hand. Complete body instrumentation is possible through custom sewn suits covering the torso or limbs. The stip sensors can be added in the suit's material at any anatomical position where bend is to be sensed.

Figure 5. The Virtex CyberGlove includes 22 resistive-bend sensors.
Three bend and one abduction sensor are used for each finger and thumb.
Thumb and pinkie cross-over and wrist rotation are also sensed.
An inexpensive input glove is the Power Glove by Mattel, designed as an input device for the Nintendo Entertainment System (videogame). It was used in a low-end system known as Virtual Reality on Five Dollars a Day (Pausch, 1991). x, y, and z location, and wrist rotation are determined using ultrasonic receivers (two on the glove) and transmitters (three, wall-mounted). Bend in the thumb and first three fingers is detected to 2 bits of resolution via strain gauges. Seventeen buttons on the forearm padding provide various select functions.
There are several 3D trackers in current use, including the Polhemus Isotrack (e.g., Ware & Baxter, 1989), the Ascension Technology Corp. Bird (see Figure 6) and the Logitech 2D/6D Mouse (e.g., Deering, 1992; Feiner, MacIntyre, & Seligmann, 1992). A transmitter or source mounted in the vicinity of the user generates an electromagnetic or ultrasonic field that is picked up by a sensor mounted on the glove (or torso, head, etc.). A cable from the sensor to the interface electronics completes the loop permitting six degree-of-freedom localization of hand position and orientation. The six degrees of freedom are the spatial coordinates with respect to the x, y, and z axes, and the angular orientations around each axis, known as pitch, roll, and yaw. The cable is sometimes called a "tether" since it confines body motion near the interface electronics. A problem with the widely used Polhemus device is that nearby metallic objects interfere with the source/sensor signal. This has inspired some alternate technologies such as optical tracking using infra-red transmitters and receivers (Wang, Chi, & Fuchs, 1990) or ceiling-mounted video cameras (Fukumoto, Mase, & Suenaga, 1992).
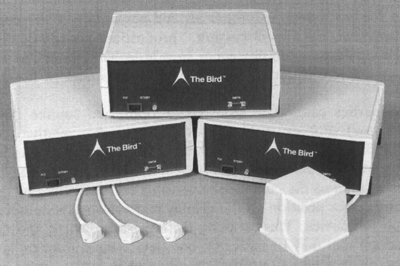
Figure 6. The Ascension Bird 3D electromagnetic tracker includes
a sensor (bottom center), a source (right), and interface electronics.
Device Properties
Input devices possess numerous properties and parameters which can enhance or limit performance. For this discussion, "properties" are the qualities which distinguish among devices and determine how a device is used and what it can do. They place a device within a "design space"--a framework for comparison and analysis.Device properties cannot be adjusted or optimized (unlike device parameters; see below). For example, cursor positioning is relative using some devices (e.g., touch tablets), but absolute with others. There is no middle ground. In relative positioning, motion (or force) applied to the device influences the motion of the cursor relative to its current position. In absolute positioning, the cursor position on the display maps to specific, absolute spatial coordinates on the device. This property distinguishes among device and determines the sorts of actions that may be easier on one device but harder on another.
"Clutching" is an interaction property inherent in tablets, mice, and other devices using relative positioning. Clutching is the process of disengaging, adjusting, and re-engaging the input device to extend its field of control. This is necessary when the tracking symbol, whether a cursor on a planar CRT or a virtual hand in 3-space, cannot move because the controlling device has reached a limit in its physical space. The most obvious example is lifting and repositioning a mouse when it reaches the edge of the mouse-pad; however, many input devices for virtual environments require constant clutching to allow the user to attain new vantages in a potentially huge task space. In such situations, clutching is implemented through a supplemental switch or through gestural techniques such as grasping. Characteristics such as this affect performance, but quantitative distinctions are difficult to measure because they are highly task dependent.
Device Models
A model is a simplified description of a system to assist in understanding the system or in describing or predicting its behaviour through calculations. The "system" in this sense is the set of input devices. Models can be broadly categorized as descriptive or predictive. Several ambitious descriptive models of input devices have been developed. One of the earliest was Buxton's (1983) taxonomy which attempted to merge the range of human gestures with the articulation requirements of devices. In Figure 7, devices are placed in a matrix with the primary rows and columns (solid lines) identifying what is sensed (position, motion, or pressure) and the number of dimensions sensed (1, 2, or 3). For example, potentiometers are 1D (left column) but a mouse is 2D (center column); trackballs are motion sensing (center row) but isometric joysticks are pressure sensing (bottom row). Secondary rows and columns (dashed lines) delimit devices manipulated using different motor skills (sub-columns) and devices operated by direct touch vs. a mechanical intermediary (sub-rows). For example, potentiometers may be rotary or sliding (left sub-columns); screen input may be direct through touch or indirect through a light pen (top sub-rows).
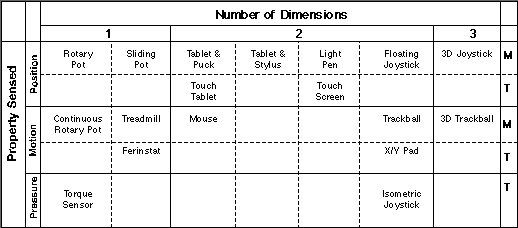
Figure 7. Buxton's (1983) taxonomy places input devices in a matrix
by the property sensed (rows), number of dimensions sensed (columns),
requisite motor skills (sub-columns), and interaction directness (sub-rows; from Buxton, 1983).
Foley, Wallace, and Chan (1984) provided a two-tiered breakdown of graphics tasks and listed devices suited to each. Seven main tasks were identified: select, position, orient, path, quantify, and text entry. Within each category a complement of sub-tasks was identified and appropriate device mappings offered. For example, two of the position sub-tasks were "direct location" and "indirect location". The touch panel was cited for the direct location task and the tablet, mouse, joystick, trackball, and cursor control keys were cited for the indirect location task. Foley et al.'s (1984) taxonomy is useful because it maps input devices to input tasks; however, it does not provide a sense of the device properties that generated the mappings. The strength of Buxton's (1983) taxonomy is its focus on the these properties.
Researchers at Xerox PARC extended the work of Buxton (1983) and Foley et al. (1984) into a comprehensive "design space" where devices are points in a parametric design space (Card, Mackinlay, & Robertson, 1990; Card, Mackinlay, & Robertson, 1991; Mackinlay, Card, & Robertson, 1991). Their model captures, for example, the possibility of devices combining position and selection capabilities with an integrated button. (Selection is a discrete property outside the purview of Buxton's taxonomy.)
The models above are descriptive. They are useful for understanding devices and suggesting powerful device-task mappings; but they are not in themselves capable of predicting and comparing alternative design scenarios. Their potential as engineering (viz., design) tools is limited.
The point above surfaced in a workshop on human-computer interaction (HCI) sponsored by National Science Foundation (Marchionini & Sibert, 1991). The participants were leading researchers in human-computer interaction. Among other things, they identified models that are important for the future of HCI. These were organized in a matrix identifying scientific vs. engineering models as relevant to human vs. machine characteristics. In Figure 8, the device models discussed above are found at the intersection of machine characteristics and descriptive scientific models. Interesting in the figure is the relative paucity of models cited as useful engineering tools, at both the human or machine level (right column). Three engineering models were cited: the Keystroke-Level (KL) model of Card, Moran, and Newell (1980); the Programmable User Model (PUM) of Young, Green, and Simon (1989); and Fitts' law (Fitts, 1954; see MacKenzie, 1992). These models are all predictive. They allow performance comparisons to be drawn before or during the design process. The idea is that interface scenarios can be explored a priori with performance comparisons drawn to aid in choosing the appropriate implementation. A challenge for HCI researchers, therefore, is to bring basic research results to the applied realm of engineering and design--to get the theory into the tools. Newell & Card (1985) elaborate further on this point.
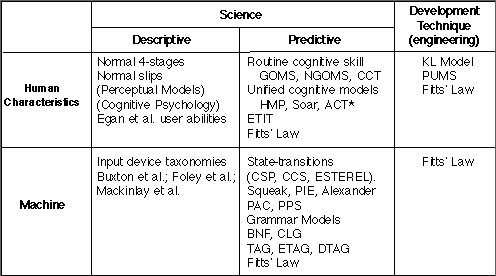
Figure 8. Models for human and machine characteristics of importance
to human-computer interaction (from Marchionini & Sibert, 1991).
Device Parameters
A parameter is any characteristic of a device or its interface which can be tuned or measured along a continuum of values. Input parameters are the sorts of features controlled or determined one way or another by designers or by system characteristics. Output parameters are the dependent variables or performance measures commonly studied in research by, for example, manipulating "device" or an input parameter as an experimental factor. Presumably a setting exists for each input parameter that yields optimal performance on the range of output parameters.
Some parameters, such as mass, resolution, or friction, are "in the device" or its electronics, and can be designed in, but cannot be tuned thereafter. Others exist in the interface software or system software. Examples are sampling rate or the control-display (C-D) relationship. Still others exist through a complex weave of transducer characteristics, interface electronics, communications channels, and software. Lag or feedback delay is one such example.
Although some parameters can be adjusted to improve performance, others are simply constraints. Resolution, sampling rate, and lag are parameters with known "optimal" settings. Resolution and sampling rate should be as high as possible, lag as low as possible. Obviously, these parameters are constrained or fixed at some reasonable level during system design. Although typical users are quite unconcerned about these, for certain applications or when operating within a real-time environments, limitations begin to take hold.
Resolution
Resolution is the spatial resolving power of the device/interface subsystem. It is usually quoted as the smallest incremental change in device position that can be detected (e.g., 0.5 cm or 1°); however, alone the specification can be misleading. This is illustrated in Figure 9, showing device position (input) vs. the position reported (output) over a spatial interval of 10 arbitrary units. The ideal case is shown in (a): The resolution is 1 unit and it is reported in precise, equal steps over the range of device movement. In (b) non-linearity is introduced. Resolution in the middle of the field of movement is very good (~0.25 units @ 5 units input), but it is poor at the extremes (~1.5 units output @ 1 unit input). Another important trait is monotonicity. Positive changes in device position should always yield positive changes in the output; however, this is often not the case as illustrated in (c). Other non-ideal characteristics (not shown) are offset, which results if the step function shown in (a) is shifted up or down; and gain, which results if the slope of the step function differs from unity. In the interface electronics, temperature sensitivity is the main culprit compromising performance. It must be remembered that the number of steps is usually quite large (e.g., thousands) and resolution spec's must be met for each degree of freedom. Very small changes in voltage or current must be sensed in the interface electronics on multiple input channels. If the transducers are magnetically-coupled, then interference or noise may be the main cause of poor resolution, non-linearity, etc.
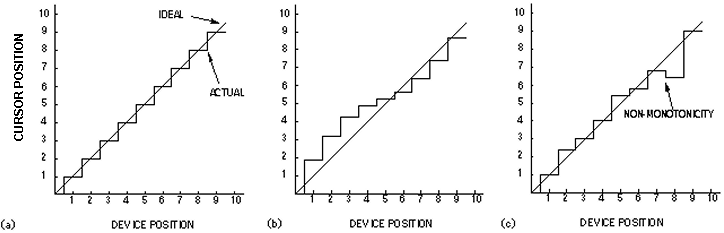
Figure 9. Resolution. (a) The ideal case for 1 unit of resolution over
10 units of movement. In (b) non-linearity is introduced showing
degraded resolution at the extremes of movement than in the center. (c)
Non-monotonicity occurs when the output fails to increase uniformly
with the input.
Touch screens, tablets, and other devices using finger or stylus input have apparent resolution problems since it is difficult to resolve finger or stylus position to the same precision as the output display (a single pixel). In fact the resolving power of the input device often exceeds that of the output device; however the input/outut mapping is limited by the contact footprint of the input device (e.g., the width of the finger tip).
3D trackers have resolution better than 1 inch and 1 degree; but this varies with the proximity of the sensor to the source and other factors. Resolution often sounds impressive in specification sheets; but when application demands increase, such as widening the field of use or combining two or three trackers, limitations become apparent. The specification sheets of 3D trackers are surprisingly sparse in their performance details. Is the resolution cited a worst-case value over the specified field of use, or is it "typical"? How will resolution degrade if two or more trackers are used? What is the effect of a large metal object five meters distant? These questions persist.
Resolution will constrain a variety of applications for 3D virtual worlds. The motions of a dancer are difficult to capture with any justice because of the large expanse of movements required. Sensing the common action of tying one's shoelaces would be a formidable task for a pair of input gloves controlling virtual hands in a simulated environment. Resolution is one constraint in this case because the movements are extremely intricate.
Sampling Rate
Sampling rate is the number of measurements per unit time (e.g., samples per second) in which the position of the input device is recorded. It is the input analog of the refresh rate for updating the output display. The rate of sampling begins to constrain performance when input or output motion is quick. Typical rates are from 10 to 100 samples per second. This is fine for many applications, but may be inadequate for real-time 3D environments which must sense and respond to the natural, sometimes rapid, motions of humans. Acts such as tying one's shoelaces or juggling involve a series of quick, intricate, coordinated hand motions that would require, among other things, a high sampling rate. In the more common application of capturing temporal cues in gestures for a sign language, sampling rate has been cited as a constraint (Fels & Hinton, 1990; Takahashi & Kishino, 1991).Sampling rate is illustrated in Figure 10 parts (a) and (b). A mouse can be wiggled back-and-forth easily at rates up to about 6 Hz. Figure 10a shows this as a sinusoid with the back-and-forth motion of the hand on the vertical axis and time on the horizontal axis. If the mouse position is sampled at 60 Hz (every 16.7 ms) with immediate updates of the screen, there will be about 10 updates of the cursor for each back and forth motion of the mouse. Cursor motion will appear as in Figure 10b. The loss of fidelity is obvious.
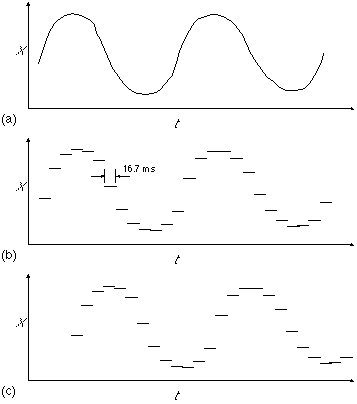
Figure 10. Sampling rate and lag. Sinusoidal back-and-forth motion
of a mouse at 6 Hz is shown in (a). At 60 Hz sampling, the cursor
appears as in (b). With three samples of lag, cursor motion is delayed as in (c).
A high sampling rate is essential in 3D virtual worlds because of spatial dynamics. In the mouse example above, the back-and-forth motion of the the hand and cursor will not exceed about 10 cm. If the controlling device is a 3D tracker attached to the head, similar back-and-forth motion (a few cm at the nose) will translate into very large movements in the visual space in very small time intervals. Smooth viewing motion necessitates a high sampling rate with immediate display refreshes.
Lag
Lag is the phenomenon of not having immediate updates of the display in response to input actions. High sampling and refresh rates are wasted if the re-drawn viewpoint does not reflect the immediately preceding sample, or if the sample does not capture the immediate habit of the user. One reason this may occur is the drawing time for the scene. If the image is complex (e.g., thousands of texture-mapped polygons with 24-bit colour), then drawing time may take two or three (or more) sampling periods. Green and Shaw (1990) describe a client-server model which lessens this effect.If updates are delayed by, say, three samples, then the cursor motion for our earlier example is degraded further as shown in Figure 10c. Lag leads to a variety of non-ideal behaviours, even motion sickness (Deyo & Ingebretson, 1989; Hettinger & Riccio, 1993; Laurel, 1991; Kreuger, 1991, p. 128). All current 3D trackers have significant lag, in the range of 30 ms to 250 ms (depending on how and where measurements are made). Furthermore, the source of the lag is not always obvious and is difficult to measure. The sampling rate for input devices and the update rate for output devices are major contributors; but lag is increased further due to "software overhead"--a loose expression for a variety of system-related factors. Communication modes, network configurations, number crunching, and application software all contribute.
Significant lags occur in most teleoperation systems, whether a remote microscope for medical diagnosis (Carr, Hasegawa, Lemmon, & Plaisant, 1992) or a space-guided vehicle (Ferrell & Sheridan, 1967). Evidently, lags more than about 1 s force the operator into a move-and-wait strategy in completing tasks. Since lag is on the order of a few hundred milliseconds in virtual environments, its effect on user performance is less apparent.
In one of the few empirical studies, Liang, Shaw, and Green (1991) measured the lag on a Polhemus Isotrak. They found lags between 85 ms and 180 ms depending on the sampling rate (60 Hz vs. 20 Hz) and communications mode (networked, polled, continuous output, direct, and client-server). Although the software was highly optimized to avoid other sources of lag, their results are strictly best-case since an "application" was not present. Substantial additional lag can be expected in any 3D virtual environment because of the graphic rendering required after each sample. Liang et al. (1991) proposed a Kalman predictive filtering algorithm to compensate for lag by anticipating head motion. Apparently predictive filtering can obviate lags up to a few hundred milliseconds; however, beyond this, the overshoot resulting from long-term prediction is more objectionable than the lag (Deering, 1992).
In another experiment to measure the human performance cost, lag was introduced as an experimental variable in a routine target selection task given to eight subjects in repeated trials (MacKenzie & Ware, 1993). Using a 60 Hz sampling and refresh rate, the minimum lag was, on average, half the sampling period or 8.3 ms. This was the "zero lag" condition. Additional lag settings were 25, 75, and 225 ms. Movement time, error rate, and motor-sensory bandwidth were the dependent variables. Under the zero lag condition (8.3 ms), the mean movement time was 911 ms, the error rate was 3.6%, and the bandwidth was 4.3 bits/s. As evident in Figure 11, lag degraded performance on all three dependent variables. At 225 ms lag (compared to 8.3 ms lag), movement times increased by 63.9% (to 1493 ms), error rates increased by 214% (to 11.3%), and bandwidth dropped by 46.5% (to 2.3 bits/s). Obviously, these figures represent serious performance decrements.
| Measure | Lag (ms) | Performance Degradation at Lag = 225 msa | |||
|---|---|---|---|---|---|
| 8.3 | 25 | 74 | 225 | ||
| Movement Time (ms) | 911 | 934 | 1058 | 1493 | 63.9% |
| Error Rate (%) | 3.6 | 3.6 | 4.9 | 11.3 | 214.0% |
| Bandwidth (bits/s) | 4.3 | 4.1 | 3.5 | 2.3 | 46.5% |
| a relative to lag = 8.3 ms | |||||
The communication link between the device electronics and the host computer may prove a bottleneck and contribute to lag as the number of sensors and their resolution increases. The CyberGlove by Virtual Technologies provides greater resolution of finger position than many gloves by including more sensors--up to 22 per glove. However, correspondingly more data are required. At the maximum data rate of 38.4 kilobaud, it takes about 5 ms just to relay the data to the host. Alone this is trivial, however a tradeoff is evident between the desire to resolve intricate hand formations and the requisite volume of "immediate" data. If we speculate on future interaction scenarios with full body suits delivering the nuances of complex motions--a common vision in VR--then it is apparent that lag will increase simply due to serial bias in the communications link. Since technological improvements can be expected on all fronts, lag may become less significant in future systems.
Optimality and Control-Display Gain
Unlike resolution, sampling rate, and lag, some parameters are "tunable" along a continuum. Presumably, a setting exists which leads to optimal human performance. This is an elusive claim, however, because no clear definition of "optimal" exists. How does one measure optimality? Quantitative measures such as task completion time or error rate are commonly used, but are narrow and do not capture important qualitative aspects of the interface. Ease of learning, skill retention, fatigue, effort, stress, etc., are important qualities of an optimal interface, but are difficult to measure. This idea has been studied extensively in an area of human factors known as human engineering (e.g., Chapanis, 1965; Wickens, 1987). As a brief example, if a relative positioning system is employed, the nuisance of clutching may go unnoticed in an experiment that only required a narrow field of motion. If frequent clutching results in a subsequent application of the same technology, then frustration or stress levels may yield highly non-optimal behaviour which eluded measurement in the research setting.Even though task completion time and error rate are easily measured in empirical tests, they are problematic. Getting tasks done quickly with few errors is obviously optimal, but the speed-accuracy tradeoff makes the simultaneous optimizing of these two output variables difficult. This is illustrated by considering control-display (C-D) gain. C-D gain expresses the relationship between the motion or force in a controller (e.g., a mouse) to the effected motion in a displayed object (e.g., a cursor). Low and high gain settings are illustrated in Figure 12.
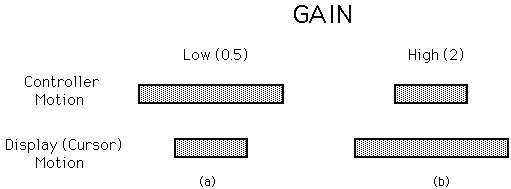
Figure 12. Contol-display (C-D) gain. (a) Under low gain a large controller movement
is required for moderate cursor movement. (b) Under high gain a slight controller
movement yields significant cursor movement.
Although a common criticism of research claiming to measure human performance on input devices is that C-D gain was not (properly) optimized, close examination reveals that the problem is tricky. Varying C-D gain evokes a trade-off between gross positioning time (getting to the vicinity of a target) and fine positioning time (the final acquisition). This effect, first pointed out by Jenkins and Connor (1949), is illustrated in Figure 13.
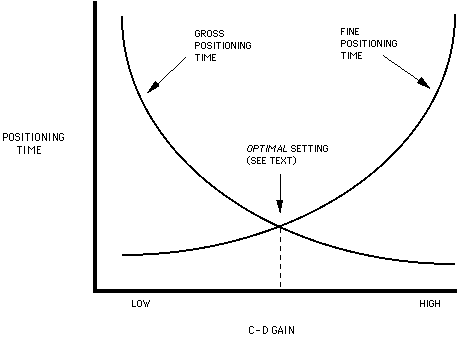
Figure 13. Low and high gains evoke a trade-off between gross positioning
time and fine positioning time. Total positioning time is minimized at the
intersection of the two.
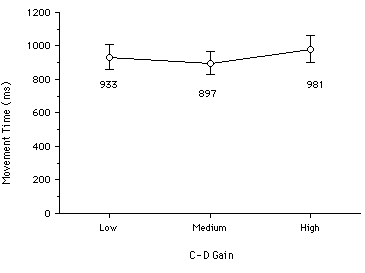
Presumably, the optimal setting is at the intersection of the two curves in Figure 13, since the total time is minimized (Chapanis & Kinkade, 1972). However, minimizing total target acquisition time is further confounded by a non-optimal (viz., higher) error rate. This was illustrated in an experiment which varied C-D gain while measuring the speed and accuracy of target acquisitions (MacKenzie & Riddersma, 1993). Twelve subjects performed repeated trials of a routine target acquisition task while C-D gain was varied through LOW, MEDIUM, and HIGH settings. As expected, the total target acquisition time was lowest at the MEDIUM setting (see Figure 14a). However, the error rate was highest at the MEDIUM setting (Figure 14b). So, the claim that an optimal C-D gain setting exists is weak at best. Other factors, such as display size (independent of C-D gain setting), also bring into question the optimality of this common input device parameter (Arnault & Greenstein, 1990).
(b)
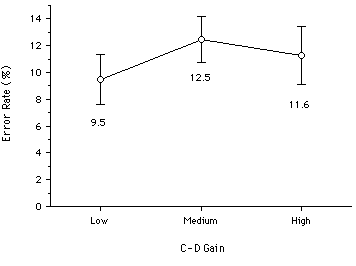
Figure 14. C-D gain and the speed-accuracy trade-off. Positioning time
is lowest under MEDIUM gain, but error rates are highest (from MacKenzie & Riddersma, 1993).
The linear, or 1st order, C-D gain shown in Figure 12 maps controller displacement to cursor (display) displacement. In practice, the C-D gain function is often non-linear or 2nd order, mapping controller velocity to some function of cursor velocity. Examples include the Apple Macintosh mouse and Xerox Fastmouse. Figure 15 illustrates a variety of 1st order (dashed lines) and 2nd order (solid lines) C-D gains.
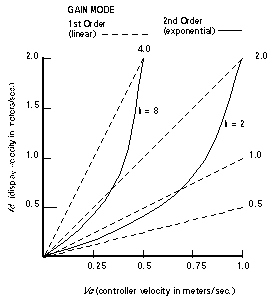
Figure 15. Linear vs. exponential mappings for C-D gain. Under exponential mapping, cursor
velocity increases non-linearly by k times the square of the controller velocity.
The 2nd order gains are of the form,
Vd = k * Vc2
where Vd is the display (cursor) velocity and Vc is the controller velocity. Note that the 2nd order function crosses several 1st order points as the controller velocity increases. A variation of this, which is easier to implement in software, uses discrete thresholds to increment k as the controller velocity increases. This relationship is
Vd = k * Vcwhere k increases by steps as Vc crosses pre-determined thresholds. Second order C-D gains have been explored as a means to boost user performance (Jackson, 1982; Rogers, 1970); however there is no evidence that performance is improved beyond the subjective preference of users. Jellinek and Card (1990) found no performance improvement using several 2nd order C-D gain relationships with a mouse, and suggested the only benefit is the smaller desktop footprint afforded by a 2nd order C-D gain.
Interaction
Today's software products invariably boast "user friendly" interfaces. This rather empty phrase would lead us to believe that human interface problems are of historical interest only. Not true. The problem of "interaction" persists. The 2D CAD tools of yesterday were precursors to today's 3D tools supporting an enhanced palette of commands and operations to control the workspace. The flat world of CRTs has stretched to its limit, and now 3D output (in numerous forms) is the challenge.
Input/Output Mappings
On the input side, challenges go beyond migrating from 2D devices (e.g., a mouse) to 3D devices (e.g., a glove). Paradigms for interaction must evolve to meet and surpass the available functionality. It is apparent that movement is of increasing importance in the design of human-computer interfaces. Static considerations in the design of interfaces, such as command languages and menu layouts, give way to the dynamics of an interface--the human is a performer acting in concert with system resources.One theme for 3D is developing interactions for mapping 2D devices into a 3D space. The mouse (for pointing), mouse buttons (for selecting or choosing), and keyboards (for specifying or valuating) are extensively used to capture and control 3D objects. Such interaction was demonstrated, for example, by Bier (1990) in manipulating polyhedrons using a technique called "snap dragging"; by Chen, Mountford, and Sellen (1988) in a three-axis rotation task using three simulated slider controls; by Houde (1992) for grasping and moving furniture in a 3D room; by Mackinlay, Card, and Robertson (1990) to specify the direction and extent of real-time navigation in 3-space; and by Phillips and Badler (1988) to manipulate limb positions and joint displacements of 3D animated human figures. These pseudo-3D interfaces do not employ gloves or other inherently 3D input technology, so the available devices--the mouse and keyboard--were exploited.
Perceptual Structure
Notwithstanding the success, low cost, and ease of implementation of the interaction styles noted above, a lingering problem is that an interaction technique must be learned. The interaction is not intuitive and, in general, there is no metaphoric link to everyday tasks. Such contrived mappings are criticized on theoretical grounds because they violate inherent structures of human perceptual processing for the input and output spaces (Jacob & Sibert, 1992). Besides force-fitting 2D devices into 3-space, there is the coincident problem of the different senses engaged by the devices vs. those stimulated by the task. Stated another way, input/output mappings of force-to-force, position-to-position, etc., are always superior to mappings such as force-to-position or force-to-motion.Consider the joysticks mentioned earlier. The three degree-of-freedom displacement joystick (Figure 3a) senses pivotal motion about a base and twist about the y or vertical axis. A strong match to perceptual structures results when the task (output space) directly matches the properties sensed (input space). For example, a task demanding pivotal positioning of an object about a point combined with y-axis rotation would be ideal for this joystick: The input/output mapping is position-to-position. The four degree-of-freedom isometric joystick in Figure 3b could perform the same task but with less fidelity, because of the force-to-position mapping.
There is some empirical support for the comparisons suggested above. Jagacinski, Repperger, Moran, Ward, and Glass (1980) and Jagacinski, Hartzell, Ward, and Bishop (1978) tested a displacement joystick in 2D target acquisition tasks. Position-to-position and position-to-velocity mappings were compared. Motor-sensory bandwidth was approximately 13 bits/s for the position-to-position system compared to only 5 bits/s for the position-to-velocity system. Kantowitz and Elvers (1988) used an isometric joystick in a 2D target acquisition task using both a force-to-position mapping (position control) and a force-to-motion mapping (velocity control). Since the application of force commonly evokes motion, a force-to-motion mapping seems closer to human perceptual processing than a force-to-position mapping. Indeed, performance was significantly better for the force-to-motion mapping compared to force-to-position mapping.
Additionally, motions or forces may be linear or rotary, suggesting that, within either the force or motion domain, linear-to-linear or rotary-to-rotary mappings will be stronger than mixed mappings. Thus, the use of a linear slider to control object rotation in the study by Chen et al. (1988) cited earlier is a weak mapping.
Jacob and Sibert (1992) focused on the "separability" of the degrees of freedom afforded by devices and required by tasks. The claim is that "non separable" degrees of freedom in a device, such as x, y, and z positioning in a 3D tracker, are a good match for a complex task with similar, non-separable degrees of freedom. Conversely, a device with "separable" degrees of freedom, such as the three degree-of-freedom joystick in Figure 3a, will work well on complex tasks with multi-, yet separable, degrees of freedom. Any complex task with relatively independent sub-tasks, such as simultaneously changing the position and colour of an object, qualifies as separable.
Gestures
By far the most common interaction paradigm heralding a new age of human-machine interaction is that of gesture. There is nothing fancy or esoteric here--no definition required. Gestures are actions humans do all the time, and the intent is that intuitive gestures should map into cyberspace without sending users to menus, manuals, or help screens. Simple actions such as writing, scribbling, annotating, pointing, nodding, etc. are gestures that speak volumes for persons engaged in the act of communicating. The many forms of sign language (formal or otherwise), or even subtle aspects of sitting, walking or driving a bicycle contain gestures.What is articulated less emphatically is that human-computer interfaces that exploit gestures are likely to spawn new paradigms of interaction, and in so doing re-define intuition. This is not a criticism. Today's intuition is the result of evolution and conscious design decisions in the past (e.g, pull-down menus). One of the most exciting aspects of interface design is imagining and experimenting with potential human-computer dialogues with gestural input.
Gestures are high-level. They map directly to "user intent" without forcing the user to learn and remember operational details of commands and options. They "chunk" together primitive actions into single directives. One application for gestural input is to recognize powerful yet simple commands (viz., strokes) for manipulating text, such as those proofreaders adopt when copy-editing a manuscript. Can editing an electronic document be as direct? Numerous prototype systems have answered a resounding "yes" (e.g., Goldberg & Goodisman, 1991; Wolf & Morrel-Samuels, 1987). The gesture of circling an object to select it is simple to implement on a mouse- or stylus-based system and can yield fast and accurate performance, particularly when multiple objects are selected (Buxton, 1986; Jackson & Roske-Hofstrand, 1989).
In an editor for 2D graphical objects, Kurtenbach and Buxton (1991) demonstrated a variety of gestures that simplify selecting, deleting, moving, or copying individual objects or groups of objects. As evident in Figure 16, the gestures are simple, intuitive, and easy to implement for a mouse or stylus. Recognition, as with speech input, remains a challenge. The open circle in Figure 16d, for example, is easily recognized by humans as a slip, but may be misinterpreted by the recognizer. Other problems include defining and constraining the scope of commands and implementing an undo operation (Hardock, 1991).
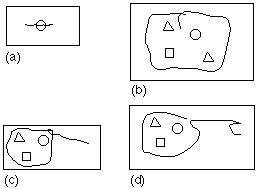
Figure 16. Gestures for graphic editing. (a) Delete an object by stroking
through it. (b) Delete a group of objects by circling and finishing the
stroke within the circle. (c) Move a group by circling and releasing outside
the circle. (d) Copy by terminating with a "c" (from Kurtenbach & Buxton, 1991).
For the artist, gestural input can facilitate creative interaction. Buxton (1986) demonstrated a simple set of gestures for transcribing musical notation. As evident in Figure 17, the most common musical notes (shown across the top) map intuitively to simple strokes of a stylus (shown below each note).
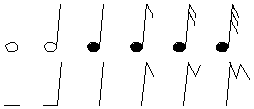
Figure 17. Gestures for transcribing musical notation. The most common
notes (top) are easily mapped to simple gestures (bottom; from Buxton, 1986).
Many touch technologies, such as the stylus or touch screen, sense pressure to 1 bit of resolution--enough to implement the "select" operation. This is insufficient to capture the richness of an artist's brush stokes, however. In a stylus-based simulation of charcoal sketching by Bleser, Sibert, and McGee (1988), pressure was sensed to 5 bits of resolution and x and y tilt to 7 bits. This permitted sketching with lines having thickness controlled by the applied pressure and texture controlled by tilt. The results were quite impressive.
The applications above are all 2D. Some of the most exciting new paradigms are those for direct, gestural interaction using an input glove in 3D virtual worlds. In fact, gesture recognition may be the easiest interaction task to cast with a glove. Pointing, delimiting a region of space, or rapid flicks of the wrist or arm are innate properties of hand and arm motion. Comparing gloves with mice and keyboards, the problems seem reversed. Selecting, specifying, choosing, etc. are easy with mice and keyboards, but defy the glove. This problem has been noted by Krueger (1991), who calls input gloves, gesture technology. Sweeping motions with the hand, as though performing an action, are natural for gloves; selecting or initiating action is hard.
Typically, a glove is the input device, and a 3D graphical hand, or virtual hand, acts as a cursor. For example, Sturman, Zeltzer, and Pieper (1989) used a DataGlove to pick up and move 3D objects. When the virtual hand viewed on the CRT crossed a threshold region near an object, grasping with the hand locked the object to the graphical hand. The object moved with the graphical hand until the grasping posture was relaxed. An alternate technique is to use the index finger to point and thumb rotation to select (Weimer & Ganapathy, 1989).
Tactile and Force Feedback
That input gloves are inherently a gesture technology follows from a feedback void. Imagine the task of reaching behind a piece of virtual equipment to turn it on. Without the sense of force or touch, this task is formidable: The virtual hand passes through the equipment without any sense of the presence of the chassis or on/off switch.It is naive to dig deep into "input" without recognizing the interdependency with output. The visual channel, as (computer) output, is primary; but the tactile and force senses are also important. This is implicit in the earlier reference to "force-to-force" as one example of an appropriate perceptual structure for input/output mapping. A few examples of force and tactile feedback pertaining to the design of interface devices follow. For detailed discussions of the mechanisms and human perception of tactile stimulation, see the chapter by Bach-Y-Rita.
A simple use of tactile feedback is shape encoding of manual controls, such as those standardized in aircraft controls for landing flaps, landing gear, the throttle, etc. (Chapanis, 1965). Shape encoding is particularly important if the operator's eyes cannot leave a primary focus point or when operators must work in the dark.
Not surprisingly, systems with tactile feedback, called tactile displays, have been developed as a sensory replacement channel for handicapped users. The most celebrated product is the Octacon, developed by Bliss and colleagues (Bliss, Katcher, Rogers, & Sheppard, 1970). This tactile reading aid, which is still in use, consists of 144 piezoelectric bimorph pins in a 24-by-6 matrix A single finger is positioned on the array (an output device) while the opposite hand maneuvers an optical pickup (an input device) across printed text. The input/output coupling is direct; that is, the tactile display delivers a one-for-one spatial reproduction of the printed characters. Reading speeds vary, but rates over 70 words/min. after 20 hr of practice have been reported (Sorkin, 1987).
A tactile display with over 7000 individually moveable pins was reported by Weber (1990). Unlike the Octacon, both hands actively explore the display. With the addition of magnetic induction sensors worn on each index finger, user's actions are monitored. A complete, multi-modal, direct manipulation interface was developed supporting a repertoire of finger gestures. This amounts to a graphical user interface without a mouse or CRT--true "touch-and-feel" interaction.
In another 2D application called Sandpaper, Minski, Ouh-Young, Steele, Brooks, and Behensky (1990) added mechanical actuators to a joystick and programmed them to behave as virtual springs. When the cursor was positioned over different grades of virtual sandpaper, the springs pulled the user's hand toward low regions and away from high regions. In an empirical test without visual feedback, users could reliably order different grades of sandpaper by granularity.
Akamatsu and Sato (1992) modified a mouse, inserting a solenoid-driven pin under the button for tactile feedback and an electromagnet near the base for force feedback (see Figure 18). Tactile stimulus to the finger tip was provided by pulsing the solenoid as the cursor crossed the outline of screen objects. Force feedback to the hand was provided by passing current through the electromagnet to increase friction between the mouse and an iron mouse pad. Friction was high while the cursor was over dark regions of the screen (e.g., icons) and was low while over light regions (background). In an experiment using a target acquisition task, movement time and accuracy were improved with the addition of tactile and force feedback compared to the vision-only condition (Akamatsu, MacKenzie, & Hasbroucq, in press). A similar system was described by Haakma (1992) using a trackball with corrective force feedback to "guide" the user toward preferred cursor positions. One potential benefit in adding force and tactile feedback is that the processing demands of the visual channel are diminished, freeing up capacity for other purposes.

Figure 18. Tactile and force feedback. Tactile feedback is provided by a
solenoid-driven pin in the mouse button. Force feedback (friction) is
provided by a magnetic field between an electromagnet inside the housing
(not shown) and an iron mouse pad (from Akamatsu, MacKenzie, & Hasbroucq, in press).
Some of the most exciting work explores tactile feedback in 3D interfaces. Zimmerman et al. (1987) modified the DataGlove by mounting piezoceramic benders under each finger. When the virtual fingertips touched the surface of a virtual object, contact was cued by a "tingling" feeling created by transmitting a 20-40 Hz sine wave through the piezoceramic transducers. This is a potential solution to the blind touch problem cited above; however providing appropriate feedback when a virtual hand contacts a virtual hard surface is extremely difficulty. Brooks, Ouh-Young, Batter, and Kilpatrick (1990) confronted the same problem:
Even in a linear analog system, there is no force applied until the probe has overshot [and] penetrated the virtual surface. The system has inertia and velocity. Unless it is critically damped, there will be an unstable chatter instead of a solid virtual barrier. (p. 183)
They added a brake--a variable damping system--and were able to provide reasonable but slightly "mushy" feedback for hard surface collision.
It is interesting to spectulate on the force equivalent of C-D gain. Indeed, such a mapping is essential if, for example, input controls with force feedback are implemented to remotely position heavy objects. The force sensed by the human operator cannot match that acting on the remote manipulator, however. Issues such as the appropriate mapping (e.g., linear vs. logarithmic), thresholds for sensing very light objects, and learning times need further exploration.
Custom hand-operated input devices (not gloves) with force feedback are also described by Bejczy (1980), Iwata (1990), and Zhai (in press).
Multi-Modal Input
The automobile is a perfect example of multi-modal interaction. Our hands, arms, feet, and legs contribute in parallel to the safe guidance of this vehicle. (A formidable challenge would be the design of a single-limb system for the same task.) With eyes, ears, and touch, we monitor the environment and our car's progress, and respond accordingly. In human-to-human communication, multi-modal interaction is the norm, as speech, gesture, and gaze merge in seamless streams of two-way intercourse. Equally rich modes of interaction have, to a limited extent, proven themselves in human-computer interaction.Multi-modal interaction has exciting roots in entertainment. The movie industry made several leaps into 3D, usually by providing the audience with inexpensive glasses that filter the screen image and present separate views to each eye. Andy Warhol's Frankenstein is the most memorable example. "Smellorama" made a brief appearance in the B-movie Polyester, staring Devine. At critical points, a flashing number on the screen directed viewers to their scratch-and-sniff card to enjoy the full aromatic drama of the scene. A prototype arcade game from the 1960s called Sensorama exploited several channels of input and output. Players sat on a "motorcycle" and toured New York city in a multi-sensory environment. Binaural 3D sounds and viewing optics immersed the rider in a visual and auditory experience. The seat and handlebars vibrated with the terrain and driver's lean, and a chemical bank behind a fan added wind and smell at appropriate spots in the tour (see Krueger, 1991).
Back in the office, multi-modal input to computing systems occurs when more than one input channel participates simultaneously in coordinating a complex task. The input channels are typically the hands, feet, head, eyes, or voice. Two-handed input is the most obvious starting point. Experimental psychologists have shown that the brain can produce simultaneously optimal solutions to two-handed coordinated tasks, even when the tasks assigned to each hand are in a different physical space and of different difficulties (Kelso, Southard, & Goodman, 1979). For human input to computing systems, Buxton and Myers (1986) offer empirical support in an experiment using a positioning/scaling task. Fourteen subjects manipulated a graphics puck with their right hand to move a square to a destination, and manipulated a slider with their left hand to re-size the square. Without prompting, subjects overwhelming adopted a multi-modal strategy. Averaged over all subjects, 41% of the time was spent in parallel activity.
Mouse input with word processors permits limited two-handed interaction. Selecting, deleting, moving, etc., are performed by point-click or point-drag operations with the mouse while the opposite hand prepares in parallel for the ensuing DELETE, COPY, or PASTE keystrokes. However, when corrections require new text, multi-modal input breaks down: The hand releases the mouse, adopts a two-handed touch-typing posture, and keys the new text. Approximately 360 ms is lost each way in "homing" between the mouse and keyboard (Card, English, & Burr, 1978).
One novel approach to reduce homing time, is to replace the mouse with a small isometric joystick embedded in the keyboard. Rutledge and Selker (1990) built such a keyboard with a "Pointing Stick" inserted between the G and H keys and a select button below the space bar (Figure 19). They conducted a simple experiment with six subjects selecting circular targets of random size and location using either the mouse or Pointing Stick. The task began and ended with a keystroke. Three measurements were taken: homing time to the pointing device, point-select time, and homing time to the keyboard. As shown in Figure 20, performance was 22% faster overall with the Pointing Stick. Homing times for the Pointing Stick were less than for the mouse, particularly for the return trip to the keyboard (90 ms vs. 720 ms). Although the mouse was faster on the point-select portions of the task, the subjects were expert mouse users; so, further performance advantages can be expected as skill develops with the Pointing Stick. We should acknowledge however, that the mouse uses position-to-position mapping and the Pointing Stick, force-to-velocity mapping. There may be inherent advantages for the mouse that will hold through all skill levels.[2]

Figure 19. The Pointing Stick. An isometric joystick is embedded
between the G and H keys and a select button is below the space bar.
| Measurement | Task Completion Time (ms)a | Point Stick Advantage | |
|---|---|---|---|
| Mouse | Pointing Stick | ||
| Homing Time to Pointing Device | 640 (110) | 390 (80) | 39% |
| Point-Select Time | 760 (190) | 1180 (350) | -55% |
| Homing Time to Keyboard | 720 (120) | 90 (130) | 875% |
| Total | 2120 (260) | 1660 (390) | 22% |
| a standard deviation shown in parentheses | |||
Stick has a 22% advantage overall (from Rutledge & Selker, 1990).
Another technique for two-handed input in text editing tasks is to free-up one hand for point-select tasks and type with the other. This is possible using a one-handed technique known as Half-QWERTY (Matias, MacKenzie, & Buxton, 1993; see Figure 21). Intended for touch typists, the Half-QWERTY concept uses half a standard keyboard in conjunction with a "flip" operation implemented on the space bar through software. Using only the left (or right) hand, typists proceed as usual except the right-hand characters are entered by pressing and holding the space bar while pressing the mirror-image key with the left hand. The right hand is free to use the mouse or other input device. The claim is that learning time for the Half-QWERTY keyboard is substantially reduced with touch typists because of skill transfer. In an experiment with 10 touch typists, an average one-handed typing speed of 35 words/minute was achieved after 10 hr of practice. Each subject attained a one-handed typing speed between 43% and 76% of their two-hand typing speed. Prolonged testing with a limited subject pool indicates that speeds up to 88% of two-handed typing speeds may be attained with one hand. Besides applications for disabled users and portable computers, the Half-QWERTY keyboard allows the full point-select capabilities of the mouse in parallel with text editing and entry.
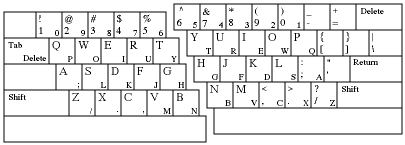
Figure 21. The Half-QWERTY keyboard. Subjects type with either the
left hand or right hand. The keys reflect in a mirror image from one
side to the other. Using the left hand, a "y" is entered by pressing
and holding the space bar while pressing "t" (from Matias, MacKenzie, & Buxton, 1993).
Speech is a powerful channel for multi-modal input. The ability to combine speech input with pointing is particularly important with 3D input, since selecting is kinesthetically difficult. The potential for speech input has been shown in numerous successful implementations. In an experiment using speech and gesture input, Hauptmann (1989) asked 36 subjects to perform rotation, translation, and scaling tasks using hand gestures and/or speech commands of their own choosing. Subjects were told a computer was interpreting their verbal commands and gestures through video cameras and a microphone; however, an expert user in an adjoining room acted as an intermediary and entered low-level commands to realize the moves. Not only did a natural tendency to adopt a multi-modal strategy appear, the strategies across subjects were surprisingly uniform. As noted, "there are no expert users for gesture communications. It is a channel that is equally accessible to all computer users" (p. 244)
Early work in multi-modal input was done at the MIT Media Lab. In Bolt's (1980) Put-that-there demo, an object displayed on a large projection screen was selected by pointing at it and saying "put that". The system responded with "where". A new location was pointed to, and replying "there" completed the move. Recent extensions to this exploit the latest 3D technology, including input gloves and eye trackers (Bolt & Herranz, 1992; Thorisson, Koons, & Bolt, 1992). A 3D object is selected by spoken words, by pointing with the hand, or simply by looking at it. Scaling, rotating, twisting, relative positioning, etc., are all implemented using two hands, speech, and eye gaze. Speech specifies what to do and when to do it; hand positions, motions, or eye gaze specify objects, spatial coordinates, relative displacements, or rotations for the moves. This is illustrated schematically in Figure 22.
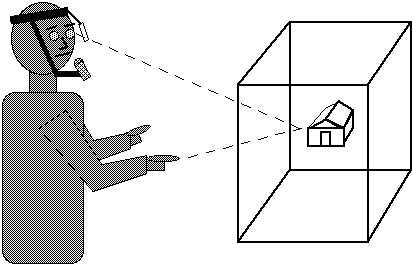
Figure 22. Multi-modal interaction. Speech, eye gaze, and
pointing combine to control a virtual world.
Challenges
In the previous pages, we have presented numerous input devices, their characteristics, and key issues for the design of interaction dialogues for high performance computing machines. Yet, the goals seems as distant as ever. There are so many new, powerful, and untapped scenarios in which to apply the latest technology, that with every problem solved a half-dozen others emerge. If it weren't for this, however, the field would be bland and routine. The excitement of new possibilities, of making technology do what was once impossible, of devising interactions to re-define intuition, is why so many dedicated researchers and designers enter and persist in this field.
There are numerous challenges ahead. So-called adaptive or intelligent systems promise to embed a familiar edict for interface designers: "know thy user". These systems will know and understand us, and mold to our strengths, weaknesses, and preferences. They'll know when we're having a good day and when a little prompting is due.
A idea behind 3D virtual worlds is to instrument all or part of the user's body, to permit natural multi-modal 3D interaction. This necessitates a large number of degrees of freedom for positioning and orientation with large volumes of data at high sampling rates. Interference between sensors, transducers, and the environment will add noise to the data. The task of embedding intelligence in the interface may be superceded by the more basic recognition of postures and gestures: What is the user doing?
Virtual worlds are the pervasive theme of this book; however many issues in input and interaction are outstanding. The promises will be met only when "deliverables" appear and enter the mainstream worlds of work and entertainment. The constraints of resolution, sampling and refresh rates, and lag will probably be met on purely technological grounds. Appropriate interaction--tactile and force feedback, gestures, multi-modal input/output, etc.--will be harder to achieve and integrate due primarily to the demands of diverse users and unique and complex applications.
Telerobotics (or remote manipulation) is an area where input devices and interaction techniques are key players. The strong interest in telerobotics is a central focus of Presence: Teleoperators and Virtual Environments, a new journal dedicated to remote and virtual environments (see also Sheridan, 1992). Unlike virtual reality, telerobotics works in a physical world where objects are too dangerous, too complex, or too distant for direct human contact. Yet, the objects are real. Since many of the interface issues are common between such virtual and phyical environments (e.g., perceptual mappings, force feedback), research and design efforts will be complementary. Matching device affordances with high fidelity interaction dialogues remains a challenge for future research and design efforts.
References
Akamatsu, M., MacKenzie, I. S., & Hasbroucq, T. (in press). A comparison of tactile, auditory, and visual feedback in a pointing task using a mouse-type device. Ergonomics. https://doi.org/10.1080/00140139508925152
Akamatsu, M., & Sato, S. (1992). Mouse-type interface device with tactile and force display: Multi-modal integrative mouse. Proceedings of the 2nd International Conference on Artificial Reality and Tele-Existence (ICAT '92), 178-182. Tokyo, Japan. https://cir.nii.ac.jp/crid/1573668924228804096
Arnault, L. Y., & Greenstein, J. S. (1990). Is display/control gain a useful metric for optimizing an interface? Human Factors, 32, 651-663. https://doi.org/10.1177/001872089003200604
Bejczy, A. K. (1980). Sensors, controls, and man-machine interface for advanced teleoperation. Science, 208, 1327-1335. https://doi.org/10.1126/science.208.4450.1327
Bier, E. A. (1990). Snap-dragging in three dimensions. Computer Graphics, 24(2), 193-204. https://doi.org/10.1145/91394.91446
Bleser, T. W., Sibert, J. L., & McGee, J. P. (1988). Charcoal sketching: Returning control to the artist. ACM Transactions on Graphics, 7, 76-81. https://doi.org/10.1145/42188.42230
Bliss, J. C., Katcher, M. H., Rogers, C. H., & Sheppard, R. P. (1970). Optical-to-tactile image conversion for the blind. IEEE Transactions on Man-Machine Systems, MMS-11, 58-65. https://doi.org/10.1109/TMMS.1970.299963
Bolt, R. (1980). Put-that-there: Voice and gesture at the graphics interface. Computer Graphics, 14(3), 262-270. https://doi.org/10.1145/800250.807503
Bolt, R., & Herranz, E. (in press). Two-handed gesture in multi-modal natural dialog. Proceedings of the ACM SIGGRAPH and SIGCHI Symposium on User Interface Software and Technology. New York: ACM. https://doi.org/10.1145/142621.142623
Brooks, Jr., F. P., Ouh-Young, M., Batter, J. J., & Kilpatrick, P. J. (1990). Project GROPE: Haptic displays for scientific visualization. Computer Graphics, 24(4), 177-185. https://doi.org/10.1145/97880.97899
Buxton, W. (1983). Lexical and pragmatic considerations of input structures. Computer Graphics, 17(1), 31-37. https://dl.acm.org/doi/pdf/10.1145/988584.988586
Buxton, W. (1986). Chunking and phrasing and the design of human-computer dialogues. In H.-J. Kugler (Ed.), Proceedings of the IFIP 10th World Computer Conference--Information Processing '86, 475-480. Amsterdam: Elsevier Science. https://doi.org/10.1016/B978-0-08-051574-8.50051-0
Buxton, W., & Myers, B. A. (1986). A study in two-handed input. Proceedings of the CHI '86 Conference on Human Factors in Computing Systems, 321-326. New York: ACM. https://doi.org/10.1145/22339.22390
Card, S. K., English, W. K., & Burr, B. J. (1978). Evaluation of mouse, rate-controlled isometric joystick, step keys, and text keys for text selection on a CRT. Ergonomics, 21, 601-613. https://doi.org/10.1080/00140137808931762
Card, S. K., Mackinlay, J. D., & Robertson, G. G. (1990). The design space of input devices. Proceedings of the CHI '90 Conference on Human Factors in Computing Systems, 117-124. New York: ACM. https://doi.org/10.1145/97243.97263
Card, S. K., Mackinlay, J. D., & Robertson, G. G. (1991). A morphological analysis of the design space of input devices. ACM Transactions on Office Information Systems, 9, 99-122. https://doi.org/10.1145/123078.128726
Card, S. K., Moran, T. P., & Newell, A. (1980). The keystroke-level model for user performance time with interactive systems. Communications of the ACM, 23, 396-410. https://dl.acm.org/doi/pdf/10.1145/358886.358895
Carr, D., Hasegawa, H., Lemmon, D., & Plaisant, C. (1992). The effects of time delays on a telepathology user interface (Tech. Rep. No. CS-TR-2874). College Park, MD: University of Maryland, Computer Science Department. https://pmc.ncbi.nlm.nih.gov/articles/PMC2248124/
Chapanis, A. (1965). Man-machine engineering. Belmont, CA: Wadsworth. https://archive.org/details/manmachineengine0000chap
Chapanis, A., & Kinkade, R. G. (1972). Design of controls. In H. P. Van Cott & R. G. Kinkade (Eds.), Human engineering guide to equipment design (pp. 345-379). Washington, DC: U.S. Government Printing Office. https://apps.dtic.mil/sti/tr/pdf/AD0758339.pdf
Chen, M., Mountford, S. J., & Sellen, A. (1988). A study in interactive 3-D rotation using 2-D control devices. Computer Graphics, 22(4), 121-129. https://doi.org/10.1145/54852.378497
Deering, M. (1992). High resolution virtual reality. Computer Graphics, 26(2), 195-202. https://dl.acm.org/doi/pdf/10.1145/133994.134039
Deyo, R., & Ingebretson, D. (1989). Implementing and interacting with real-time microworlds. Course Notes 29 for SIGGRAPH '89. New York: ACM.
Feiner, S., MacIntyre, B., & Seligmann, D. (1992). Annotating the real world with knowledge-based graphics on a see-through head-mounted display. Proceedings of Graphics Interface '92, 78-85. Toronto: Canadian Information Processing Society. https://dl.acm.org/doi/abs/10.5555/155294.155304
Fels, S. S., & Hinton, G. E. (1990). Building adaptive interfaces with neural networks: The glove-talk pilot study. Proceedings of INTERACT '90, 683-688. Amsterdam: Elsevier Science. https://dl.acm.org/doi/abs/10.5555/647402.725595
Ferrell, W. R., & Sheridan, T. B. (1967). Supervisory control of remote manipulation. IEEE Spectrum, 4(10), 81-88. https://doi.org/10.1109/MSPEC.1967.5217126
Fitts, P. M. (1954). The information capacity of the human motor system in controlling the amplitude of movement. Journal of Experimental Psychology, 47, 381-391. https://psycnet.apa.org/doi/10.1037/h0055392
Foley, J. D., Wallace, V. L., & Chan, P. (1984). The human factors of computer graphics interaction techniques. IEEE Computer Graphics and Applications, 4(11), 13-48. https://doi.org/10.1109/MCG.1984.6429355
Fukumoto, M., Mase, K., & Suenaga, Y. (1992, May). Finger-pointer: A glove free interface. Poster presented at the CHI '92 Conference on Human Factors in Computing Systems, Monterey, CA. https://doi.org/10.1145/1125021.1125079
Goldberg, D., & Goodisman, A. (1991). Stylus user interfaces for manipulating text. Proceedings of the ACM SIGGRAPH and SIGCHI Symposium on User Interface Software and Technology, 127-135. New York: ACM. https://dl.acm.org/doi/pdf/10.1145/120782.120796
Green, M., & Shaw, C. (1990). The DataPaper: Living in the virtual world. Proceedings of Graphics Interface '90, 123-130. Toronto: Canadian Information Processing Society. https://www.researchgate.net/profile/Christopher-Shaw-11/publication/262163640_The_DataPaper_living_in_the_virtual_world/links/562af1fc08ae518e347f84f0/The-DataPaper-living-in-the-virtual-world.pdf
Green, M., Shaw, C., & Pausch, R. (1992). Virtual reality and highly interactive three dimensional user interfaces. CHI '92 Tutorial Notes. New York: ACM.
Greenstein, J. S., & Arnault, L. Y. (1987). Human factors aspects of manual computer input devices. In G. Salvendy (Ed.), Handbook of human factors (pp. 1450-1489). New York: Wiley.
Haakma, R. (1992). Contextual motor feedback in cursor control. Poster presented at the CHI '92 Conference on Human Factors in Computing Systems, Monterey, CA. https://doi.org/10.1145/1125021.1125078
Hardock, G. (1991). Design issues for line-driven text editing/annotation systems. Proceedings of Graphics Interface '91, 77-84. Toronto: Canadian Information Processing Society. https://graphicsinterface.org/wp-content/uploads/gi1991-11.pdf
Hauptmann, A. G. (1989). Speech and gestures for graphic image manipulation. Proceedings of the CHI '89 Conference on Human Factors in Computing Systems, 241-245. New York: ACM. https://doi.org/10.1145/67449.67496
Hettinger, L. J., & Riccio, G. E. (1993). Visually induced motion sickness in virtual environments. Presence, 1, 306-310. https://doi.org/10.1162/pres.1992.1.3.306
Houde, S. (1992). Iterative design of an interface for easy 3-D direct manipulation. Proceedings of the CHI '92 Conference on Human Factors in Computing Systems, 135-142. New York: ACM. https://doi.org/10.1145/142750.142772
Iwata, H. (1990). Artificial reality with force-feedback: Development of desktop virtual space with compact master manipulator. Computer Graphics, 24(4), 165-170. https://doi.org/10.1145/97880.97897
Jackson, A. (1982). Some problems in the specification of rolling ball operating characteristics. International Conference on Man/Machine Systems, 103-106. Middlesex, UK: Thomas/Weintroub.
Jackson, J. C., & Roske-Hofstrand, R. J. (1989). Circling: A method of mouse-based selection without button presses. Proceedings of the CHI '89 Conference on Human Factors in Computing Systems, 161-166. New York: ACM. https://doi.org/10.1145/67449.67483
Jacob, R. J. K., & Sibert, L. E. (1992). The perceptual structure of multidimensional input device selection. Proceedings of the CHI '92 Conference on Human Factors in Computing Systems, 211-218. New York: ACM. https://doi.org/10.1145/142750.142792
Jagacinski, R. J., Hartzell, E. J., Ward, S., & Bishop, K. (1978). Fitts' law as a function of system dynamics and target uncertainty. Journal of Motor Behavior, 10, 123-131. https://doi.org/10.1080/00222895.1978.10735145
Jagacinski, R. J., Repperger, D. W., Moran, M. S., Ward, S. L., & Glass, B. (1980). Fitts' law and the microstructure of rapid discrete movements. Journal of Experimental Psychology: Human Perception and Performance, 6, 309-320. https://psycnet.apa.org/doi/10.1037/0096-1523.6.2.309
Jellinek, H. D., & Card, S. K. (1990). Powermice and user performance. Proceedings of the CHI '90 Conference on Human Factors in Computing Systems, 213-220. New York: ACM. https://doi.org/10.1145/97243.97276
Jenkins, W. L., & Connor, M. B. (1949). Some design factors in making settings on a linear scale. Journal of Applied Psychology, 33, 395-409. https://psycnet.apa.org/doi/10.1037/h0056573
Kantowitz, B. H., & Elvers, G. C. (1988). Fitts' law with an isometric controller: Effects of order of control and control-display gain. Journal of Motor Behavior, 20, 53-66. https://doi.org/10.1080/00222895.1988.10735432
Kelso, J. A. S., Southard, D. L., & Goodman, D. (1979). On the coordination of two-handed movements. Journal of Experimental Psychology: Human Perception and Performance, 5, 229-238. https://haskinslabs.org/sites/default/files/files/Reprints/HL0265.pdf
Krueger, M. W. (1991). Artificial reality II. Reading, MA: Addison-Wesley. https://archive.org/details/artificialrealit00krue
Kurtenbach, G., & Buxton, B. (1991). GEdit: A testbed for editing by contiguous gestures. SIGCHI Bulletin, 23(2), 22-26. https://doi.org/10.1145/122488.122490
Laurel, B. (1991). Computers as theatre. Reading, MA: Addison Wesley. https://www.cs.cmu.edu/~social/reading/Laurel-ComputersAsTheatre.pdf
Liang, J., Shaw, C., & Green, M. (1991). On temporal-spatial realism in the virtual reality environment. Proceedings of the ACM SIGGRAPH and SIGCHI Symposium on User Interface Software and Technology, 19-25. New York: ACM. https://dl.acm.org/doi/pdf/10.1145/120782.120784
MacKenzie, I. S. (1992). Fitts' law as a research and design tool in human-computer interaction, Human-Computer Interaction, 7, 91-139. https://doi.org/10.1207/s15327051hci0701_3
MacKenzie, I. S., & Riddersma, S. (1993). CRT vs. LCD: Empirical evidence for human performance differences. Submitted for publication.
MacKenzie, I. S., & Ware, C. (1993). Lag as a determinant of human performance on interactive systems. Proceedings of the INTERCHI'93 Conference on Human Factors in Computing Systems, 488-493. New York: ACM. https://doi.org/10.1145/169059.169431
Mackinlay, J. D., Card, S. K., & Robertson, G. G. (1990). Rapid controlled movement through a virtual 3D workspace. Computer Graphics, 24(4), 171-176. https://doi.org/10.1145/97879.97898
Mackinlay, J. D., Card, S. K., & Robertson, G. G. (1991). A semantic analysis of the design space of input devices. Human-Computer Interaction, 5, 145-190. https://doi.org/10.1080/07370024.1990.9667153
Marchionini, G., & Sibert, J. (1991). An agenda for human-computer interaction: Science and engineering serving human needs. SIGCHI Bulletin, 23(4), 17-32. https://doi.org/10.1145/126729.126741
Matias, E., MacKenzie, I. S., & Buxton, W. (1993). Half-QWERTY: A one-handed keyboard facilitating skill transfer from QWERTY. Proceedings of the INTERCHI'93 Conference on Human Factors in Computing Systems, 88-94. New York: ACM. https://dl.acm.org/doi/pdf/10.1145/169059.169097
Minski, M., Ouh-Young, M. Steele, O., Brooks, Jr., F. P., & Behensky, M. (1990). Feeling and seeing: Issues in force display. Computer Graphics, 24(2), 235-270. https://dl.acm.org/doi/pdf/10.1145/91385.91451
Newell, A., & Card, S. K. (1985). The prospects for psychological science in human-computer interaction. Human-Computer Interaction, 1, 209-242. https://doi.org/10.1207/s15327051hci0103_1
Pausch, R. (1991). Virtual reality on five dollars a day. Proceedings of the CHI '91 Conference on Human Factors in Computing Systems, 265-270. New York: ACM. https://doi.org/10.1145/108844.108913
Phillips, C. B., & Badler, N. I. (1988). Jack: A toolkit for manipulating articulated figures. Proceedings of the ACM SIGGRAPH Symposium on User Interface Software and Technology, 221-229. New York: ACM. https://doi.org/10.1145/62402.62436
Rogers, J. G. (1970). Discrete tracking performance with limited velocity resolution. Human Factors, 12, 331-339. https://doi.org/10.1177/001872087001200309
Rutledge, J. D., & Selker, T. (1990). Force-to-motion functions for pointing. Proceedings of IFIP INTERACT'90: Human-Computer Interaction, 701-706. Asmterdam: Elsevier. https://dl.acm.org/doi/abs/10.5555/647402.725310
Sheridan, T. B. (1992). Telerobotics, automation, and human supervisory control. Cambridge, MA: MIT Press.
Sherr, S. (Ed.). (1988). Input devices. San Diego, CA: Academic Press.
Sorkin, R. D. (1987). Design of auditory and tactile displays. In G. Salvendy (Ed.), Handbook of human factors (pp. 549-576). New York: Wiley.
Sturman, D. J., Zeltzer, D., & Pieper, S. (1989). Hands-on interaction with virtual environments. Proceedings of the ACM SIGGRAPH Symposium on User Interface Software and Technology, 19-24. New York: ACM. https://doi.org/10.1145/73660.73663
Takahashi, T., & Kishino, F. (1991). Hand gesture coding based on experiments using a hand gesture interface device. SIGCHI Bulletin, 23(2), 67-73. https://doi.org/10.1145/122488.122499
Thorisson, K. R., Koons, D. B., & Bolt, R. A. (1992). Multi-modal natural dialogue. Proceedings of the CHI '92 Conference on Human Factors in Computing Systems, 653-654. New York: ACM. https://dl.acm.org/doi/pdf/10.1145/142750.150714
Wang, J.-F., Chi, V., & Fuchs, H. (1990). A real-time optical 3D tracker for head-mounted display systems. Computer Graphics, 24(2), 205-215. https://doi.org/10.1145/91394.91447
Ware, C., & Baxter, C. (1989). Bat brushes: On the uses of six position and orientation parameters in a paint program. Proceedings of the CHI '89 Conference on Human Factors in Computing Systems, 155-160. New York: ACM. https://doi.org/10.1145/67449.67482
Weber, G. (1990). FINGER: A language for gesture recognition. Proceedings of INTERACT '90, 689-694. Amsterdam: Elsevier Science. https://dl.acm.org/doi/abs/10.5555/647402.725286
Weimer, D., & Ganapathy, S. K. (1989). A synthetic visual environment with hand gesturing and voice input. Proceedings of the CHI '89 Conference on Human Factors in Computing Systems, 235-240. New York: ACM. https://doi.org/10.1145/67450.67495
Wickens, C. D. (1987). Engineering psychology and human performance. New York: Harper Collins. https://doi.org/10.4324/9781315665177
Wolf, C. G., & Morrel-Samuels, P. (1987). The use of hand-gestures for text-editing. International Journal of Man-Machine Studies, 27, 91-102. https://doi.org/10.1016/S0020-7373(87)80045-7
Young, R. M., Green, T. G. R., & Simon, T. (1989). Programmable user models for predictive evaluation of interface design. Proceedings of the CHI '89 Conference on Human Factors in Computing Systems, 15-19. New York: ACM. https://doi.org/10.1145/67450.67453
Zhai, S. (in press). Investigation of feel for 6DOF inputs: Isometric and elastic rate control for manipulation in 3D environments. Proceedings of the Human Factors and Ergonomics Society 37th Annual Meeting - 1993. Santa Monica: Human Factor Society. https://doi.org/10.1177/154193129303700415
Zimmerman, T. G., Lanier, J., Blanchard, C., Bryson, S., & Harvill, Y. (1987). A hand gesture interface device. Proceedings of the CHI+GI '87 Conference on Human Factors in Computing Systems, 189-192. New York: ACM. https://doi.org/10.1145/1165387.275628