VADViT: Vision Transformer-Driven Memory Forensics for Malicious Process Detection and Explainable Threat Attribution
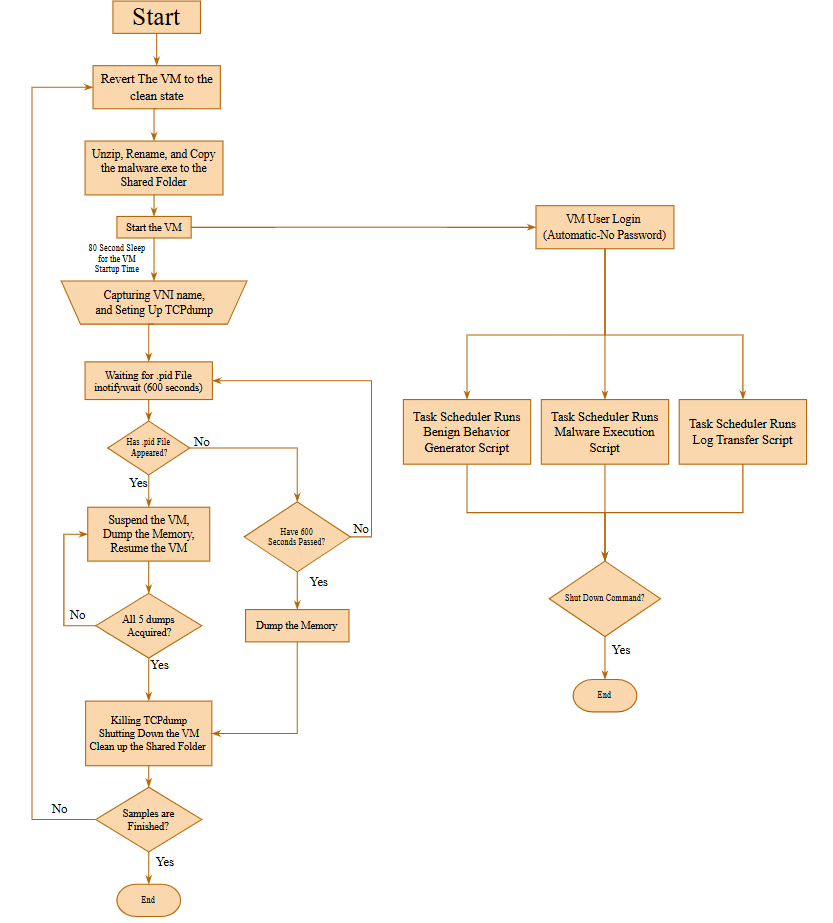
Modern malware’s complexity challenges traditional detection and existing ML-based memory forensics, which often rely on outdated features and struggle with large-scale data. We propose VADViT, a vision transformer model that converts VAD memory regions into fused Markov, entropy, and intensity images for effective malware classification, achieving 99% binary accuracy and 92% macro F1. Supported by the new BCCC-MalMem-SnapLog-2025 dataset, VADViT also improves forensic efficiency by using attention-based sorting to focus on the most relevant memory areas.